L'IA offre un potentiel significatif pour rationaliser et optimiser la gestion du backlog Produit, mais son adoption nécessitera de trouver un équilibre judicieux entre automatisation et validation humaine, tout en assurant la transparence et en atténuant les risques de biais.
L'arrivée de l'intelligence artificielle (IA) bouscule les pratiques Agile. Que signifie encore "être Agile" à l'ère de l'IA? Cette série d'articles dresse un panorama des changements culturels et méthodologiques à prévoir au sein des organisations.
Les LLM sont des modèles de Machine learning capables de générer du texte, de traduire des langues, d'écrire différents types de contenu créatif et de répondre à des questions de manière pertinente. Ils sont encore en développement, mais ils ont le potentiel de révolutionner la façon dont nous interagissons avec la technologie.
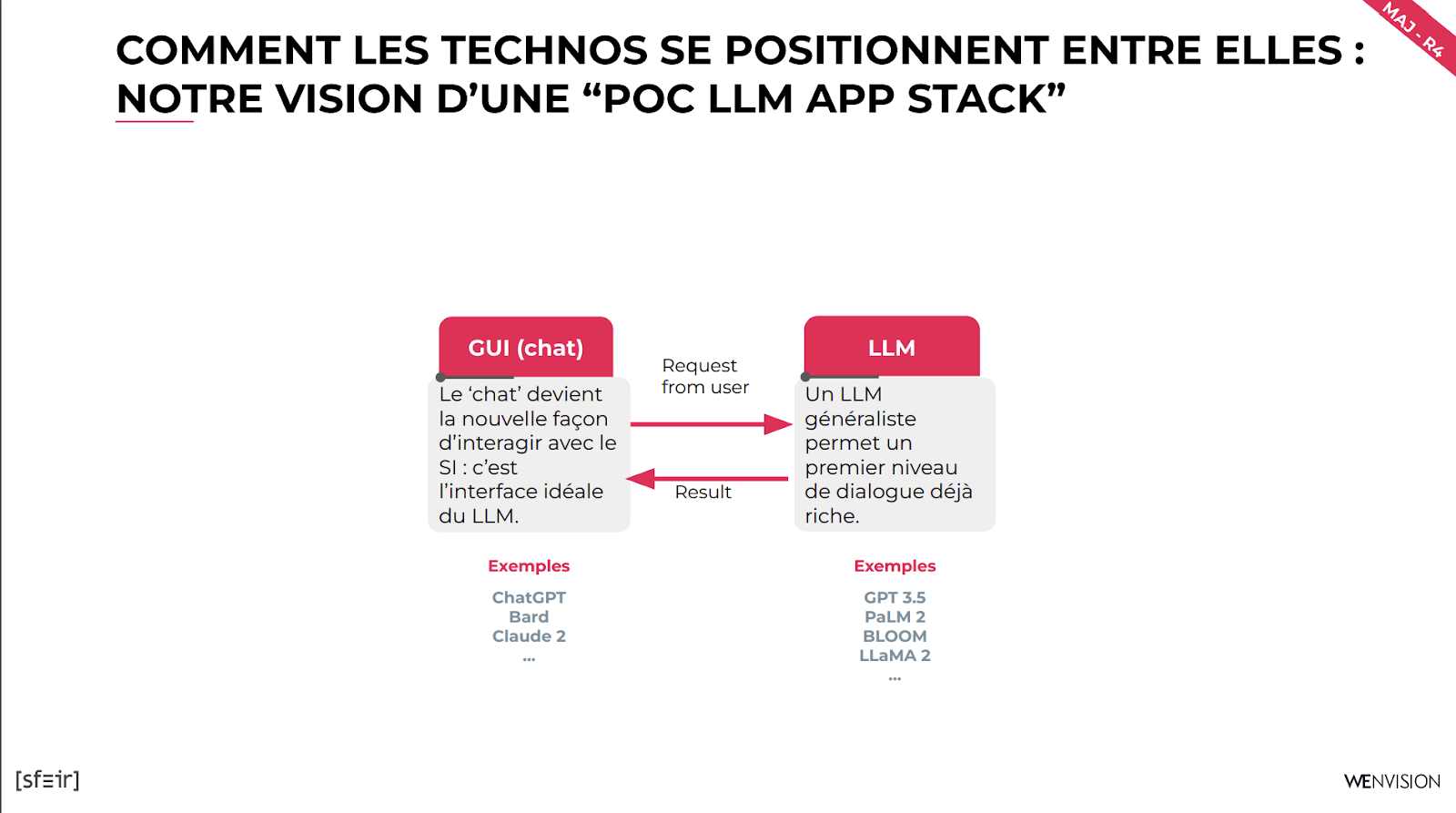
Architecture d'un POC basé sur la technologie LLM
Une architecture d'application LLM basique pour faire un POC est composée de deux éléments principaux : une interface homme-machine (IHM) de chat et un LLM.
L'IHM de chat
L'IHM de chat est une interface simple qui permet à l'utilisateur de communiquer avec le LLM. Elle est généralement basée sur un chat en ligne, où l'utilisateur peut saisir une requête et le LLM répondra avec un texte.
Le LLM
Le LLM est l'algo qui génère le texte. Il est accédé via une API. Il est capable de générer du texte qui est à la fois grammaticalement correct et pertinent pour le contexte de la conversation.
Limitations de l'architecture
Cette architecture est simple et facile à mettre en place, mais elle présente un certain nombre de limitations.
Sécurité : L'IHM de chat est généralement ouverte à tous, ce qui signifie que n'importe qui peut interagir avec le LLM. Cela peut poser un problème de sécurité, car le LLM peut être utilisé pour générer du contenu malveillant ou offensant.
Précision : Le LLM est formé sur un ensemble de données spécifique, ce qui signifie qu'il peut ne pas être précis pour tous les types de tâches.
Performances : Le LLM peut être lent à répondre, ce qui peut être frustrant pour l'utilisateur.
Conclusion
Cette architecture est utile pour tester un LLM ou faire des démonstrations en interne. Cependant, elle ne doit pas être mise entre les mains d'un utilisateur final. Pour une application LLM en production, il est important de prendre en compte les limitations de cette architecture et de mettre en place des mesures de sécurité et de précision supplémentaires.
L'arrivée de l'intelligence artificielle (IA) bouscule les pratiques Agile. Que signifie encore "être Agile" à l'ère de l'IA? Cette série d'articles dresse un panorama des changements culturels et méthodologiques à prévoir au sein des organisations.
Qui mieux qu'un moteur de GenAI pour nous éclairer sur ses bénéfices et ses limites. Nous lui avons demandé et voici le résultat ! Un éclairage pour les leaders cherchant à tirer parti de l'IA tout en préservant l'essence du coach Agile humain.
Que signifiera “être agile à l’ère de l’IA”? Nous décryptons ici les prédictions, voire spéculations de Henrik Kniberg sur l’avenir proche de l’Agilité combinée à l’IA.