Implementing Adaptive Agentic in Production with RAISE (Part 1)
Understanding Adaptive Agentic Systems
Agentic AI is everywhere. We talk about it, we build with it, we sell it. But between impressive demos and systems that hold up in production, there's a chasm that few manage to cross.
This three-part series explores this chasm and how to bridge it.
Part 1 - Agentic That "Almost Works" Doesn't Work
We lay the conceptual foundations. Why current agentic systems struggle to move from POC to production, what the systematic pitfalls are, and what principles to build upon to avoid them. The problem isn't that it crashes, it's that it works "sort of", and to reach the production stage, it doesn't achieve the desired level of reliability. Most importantly, we don't know how to improve it because we didn't equip the system for that from the start.
Part 2 - Adaptive Agentic: Principles of AI That Grows
We move to the vision. The principles of adaptive agentic systems, how to build systems that don't just execute but observe, learn, and grow. We explore the architectural pillars that make this vision possible.
Part 3 - Implementing Adaptive Agentic in Production with RAISE
→ Part 3a: Architecture, design and operationalization
→ Part 3b: Multi-agent orchestration and dynamic knowledge graph
We move to implementation. How these principles translate concretely into RAISE, the generative AI platform of the SFEIR group. What architectures, what design choices, what mechanics to put in place. From concept to operational reality.
Because between being right on paper and running a system in production, there's a whole world. And it's precisely that world we're going to explore.
Agentic AI is everywhere. We talk about it, we build with it, we sell it. But between impressive demos and systems that hold up in production, there's a chasm that few manage to cross.
In the first part, we established the diagnosis: current agentic systems fail to move from POC to production, lacking reliability, observability, and learning capacity.
In the second part, we presented the vision: adaptive agentic systems and their fundamental principles (self-observability, the three cognitive pillars, living organizational memory, multi-agent architecture, evolving human-in-the-middle).
In this third part, we move to implementation: how these principles translate into an AI platform, specifically RAISE, the generative AI platform of the SFEIR group. From operational features to concrete demonstrations.
Because between being right on paper and running a system in production, there's all the implementation. And that's precisely where everything plays out. How to set up an agentic AI system, demonstrated with an AI4Ops implementation!
RAISE: An Implementation Accelerator, Not Just Another Framework
Let's be clear from the start: RAISE is not yet another AI framework joining the cohort of available solutions.
RAISE is above all an implementation accelerator. A platform that enables putting a large number of building blocks and frameworks into production in a reliable and controlled manner, with a coherent architecture that facilitates extensions.
This clean and modular architecture is a major asset. When I joined WEnvision and the SFEIR Group, and discovered their vision of conversational IT systems and RAISE's hexagonal/modular approach, I realized we wouldn't have to rebuild everything. Indeed, RAISE's architecture allowed us to easily implement these new agentic concepts naturally, through extension rather than refactoring.
It's this extension capability that makes the difference between a POC and a production-ready system. You don't rebuild everything with each evolution. You extend, you compose, you orchestrate.
Let's now see concretely how we translated the principles of adaptive agentic systems into operational features in RAISE, for IT support.
Self-Observability: Seeing What the Agent Thinks
The first feature we implemented is systematic self-observability. Not as an option. As a foundational building block, present on every response from any assistant or agent in a network, available to administrators, managers, and supervisors of adaptive agents.
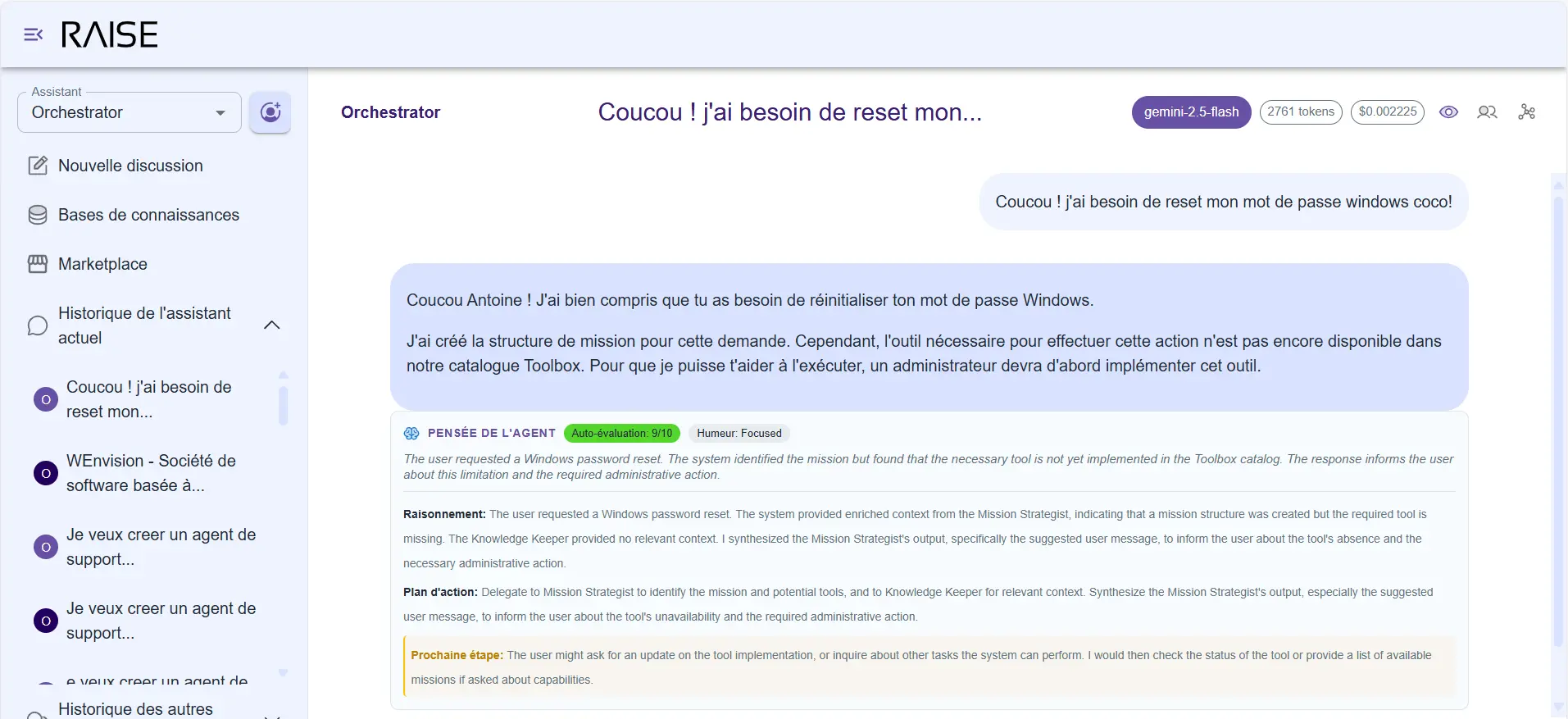
RAISE Interface: "Agent Thinking" automatically exposes its reasoning, self-evaluation, and action plan
What You See
Every time an agent responds, it automatically generates an observation of its own reasoning. This observation isn't visible by default in the conversation (to avoid polluting the exchange), but it's accessible via a simple toggle, and most importantly in the database for future analyses.
When you activate it, you see a compact card that exposes:
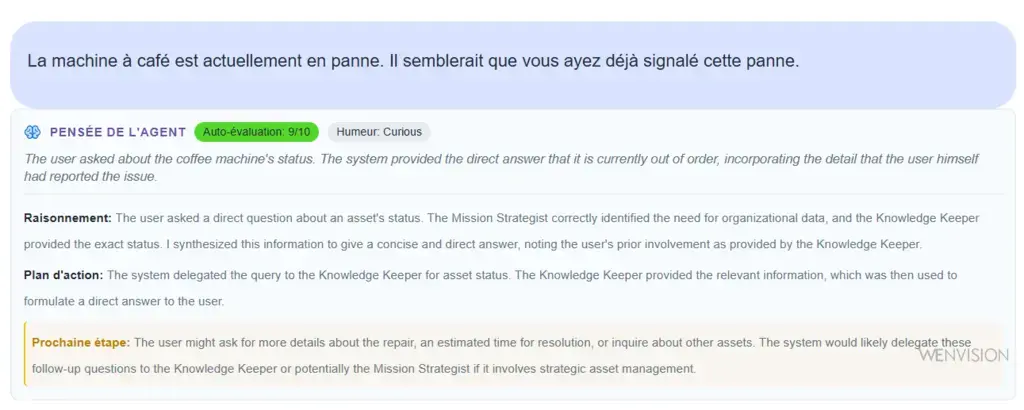
Self-observation card: agent thinking, self-evaluation (9/10), detailed reasoning and projected action plan
The Summary: "The user is asking to unblock a CI/CD pipeline that's failing. The problem seems to stem from a missing dependency."
The Self-Evaluation: a score from 0 to 10 that the agent gives itself on its response.
- 8/10: "I have access to logs and context, but haven't verified the configuration yet."
- 3/10: "I'm lacking information about this project's architecture."
The Detected Mood: "The user seems rushed and frustrated."
The Internal Thinking: "The pipeline is probably failing at the testing stage. The user mentioned it worked yesterday, so it's probably related to a recent change."
The Plan:
- Analyze pipeline logs
- Check recent changes in dependencies
- Propose a workaround if necessary
The Next Step: "Wait for the user to give me access to Jenkins logs or confirm which pipeline is involved."
Why Is This Essential?
Without this observability, you're blind. The agent responds, but you don't know:
- If it properly understood your request.
- If it's confident in its response.
- Where it's hesitating.
- What plan it has in mind.
- What it's missing to respond better.
With systematic observability, every interaction becomes transparent. You can see when the agent loses confidence, when it makes risky assumptions, when its plan is shaky.
And most importantly: you can analyze patterns. "Why does the agent consistently give itself 4/10 on this type of question?" → It's missing information in the knowledge graph. You enrich the graph, and suddenly confidence rises to 8/10.
Without this visibility, you can't improve. With it, every problem becomes identifiable and addressable.
The Base Agent Network: Thinking in Parallel
Observability is seeing. But to act intelligently, you need an architecture that allows parallel reasoning, context fusion, and informed decision-making.
Here's how the base agent network works in RAISE for any adaptive agent.
Three Roles, One Objective
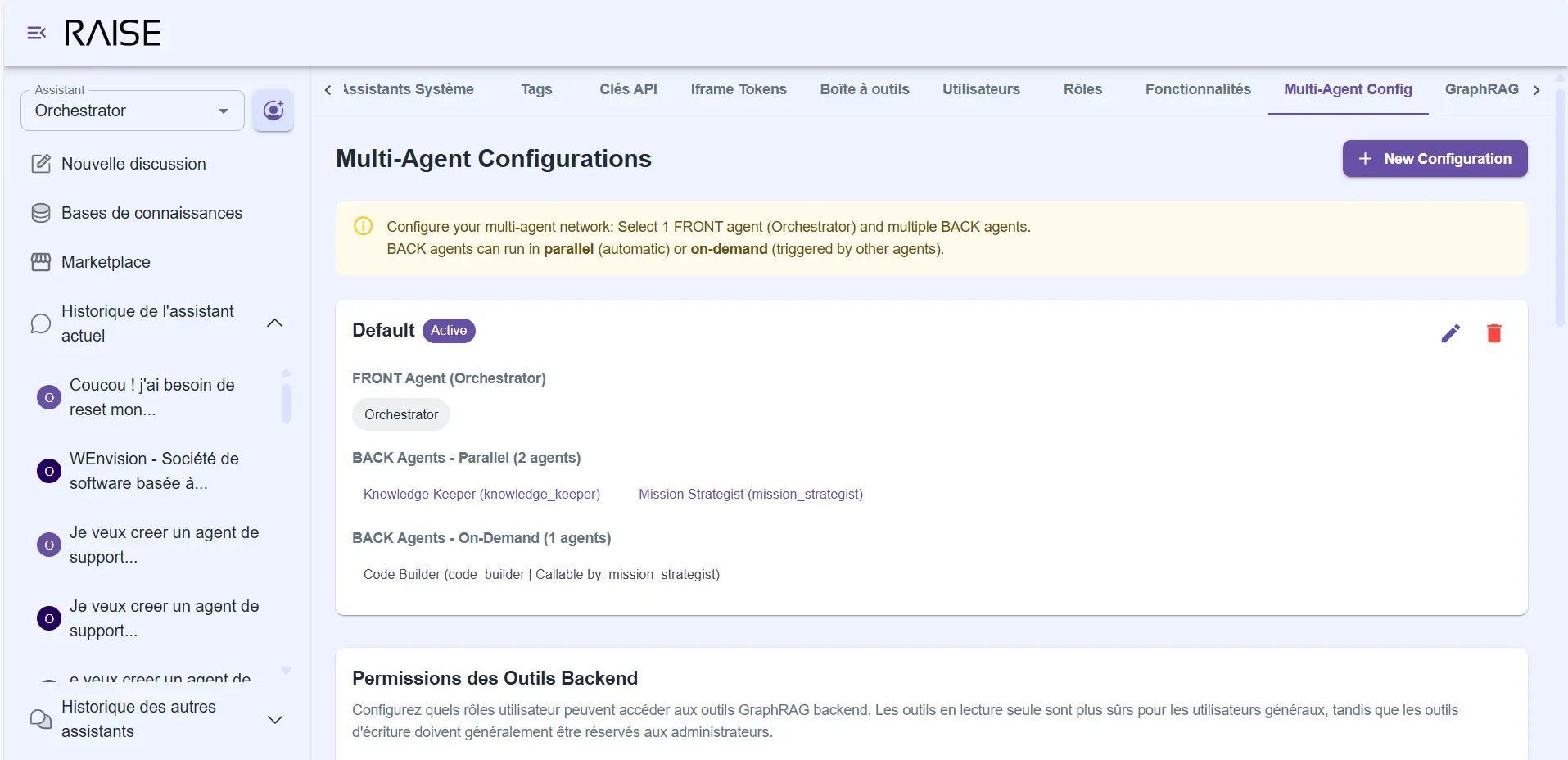
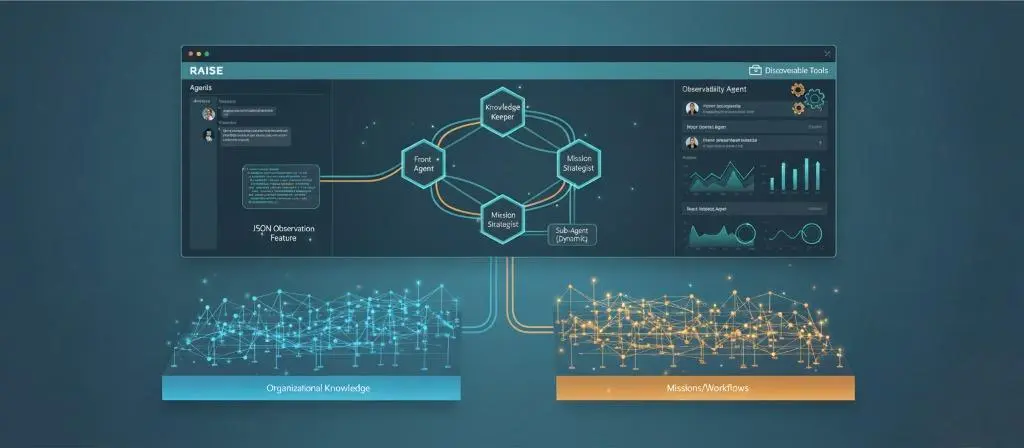
Multi-agent configuration: 1 Front Agent (Orchestrator) + 2 parallel Back Agents (Knowledge Keeper, Mission Strategist) + 1 on-demand (Code Builder)
The Front Agent is your point of contact. It's the one that receives your messages, orchestrates the work, and responds to you. But it doesn't do all the reasoning alone.
When you ask it a question, it dispatches it in parallel to two specialized agents:
- The Knowledge Keeper knows your organization. It knows who does what, what your tech stack is, how you work, what decisions were made in the past. When you say "contact someone from accounting", it's the one that knows who to contact.
- The Mission Strategist knows your objectives. It knows what projects you're working on, what tasks are in progress, where different missions stand. When you ask "where does project X stand", it's the one with the answer.
Why in Parallel?
Because that's how you naturally reason. When we ask you a professional question, you don't first think about organizational context, then about your mission. You do both simultaneously.
"Who can help me with this topic?" → You simultaneously think about people's skills (org context) and who's available/aligned with priorities (mission context).
The Front Agent receives both analyses, merges them, and builds a response that makes sense both organizationally and strategically.
It's not a cascade of API calls. It's true cognitive collaboration.
This approach triggers multiple LLM calls for a single user input, but this fragmentation allows the use of lighter, faster models with more interesting costs than traditional large LLMs.
Knowledge Graphs: Two Specialized Memories
These agents don't reason on nothing. They each rely on a knowledge structure that evolves with your organization.
The Knowledge Keeper Graph: Organizational Memory
The Knowledge Keeper maintains a graph that structures three dimensions of your organization:
- Human organization: who is part of which team? Who is responsible for what? How do departments articulate?
- The technical dimension: what stack do you use? How is your infrastructure architected? Where to find documentation?
- Culture and history: how do you make decisions? What are your work conventions? Why did you make such a choice 6 months ago?
This graph builds progressively. Throughout conversations, the agent detects structuring information: "Ah, you mention that Sarah joined the DevOps team. Can I add that to the graph?" You validate. The graph grows. The agent becomes increasingly relevant.
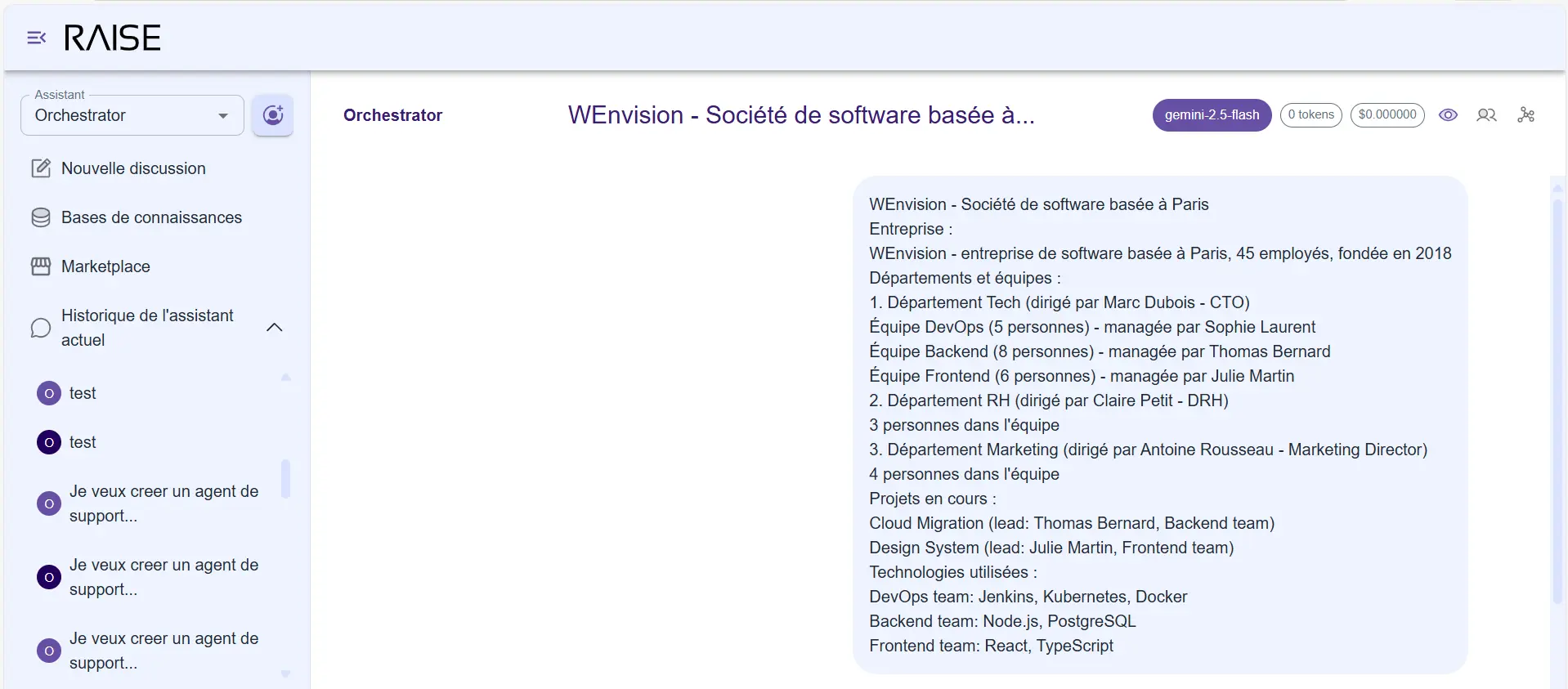
The user sends a fictional org chart of WEnvision to the system
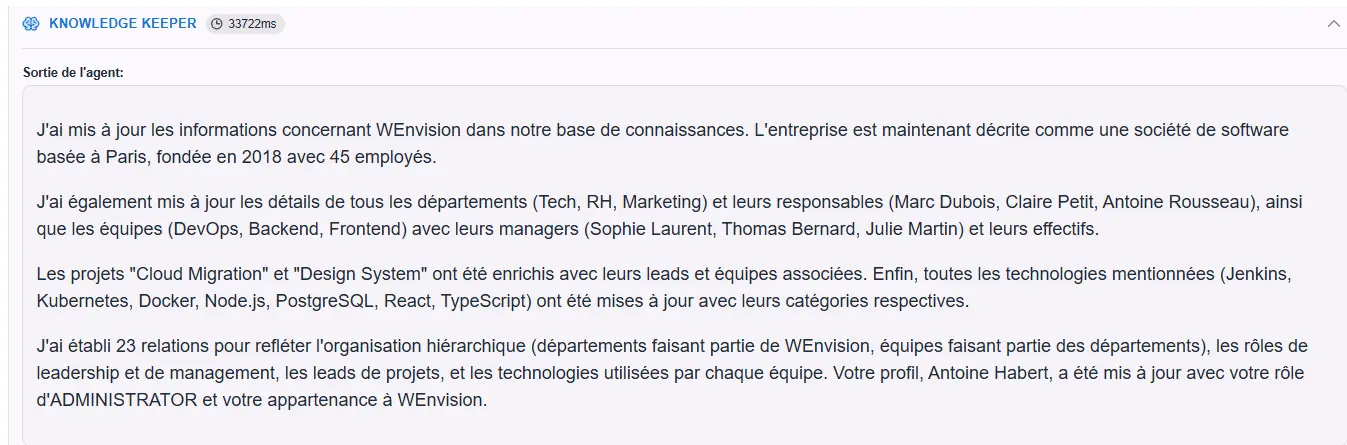
The Knowledge Keeper interprets organizational information
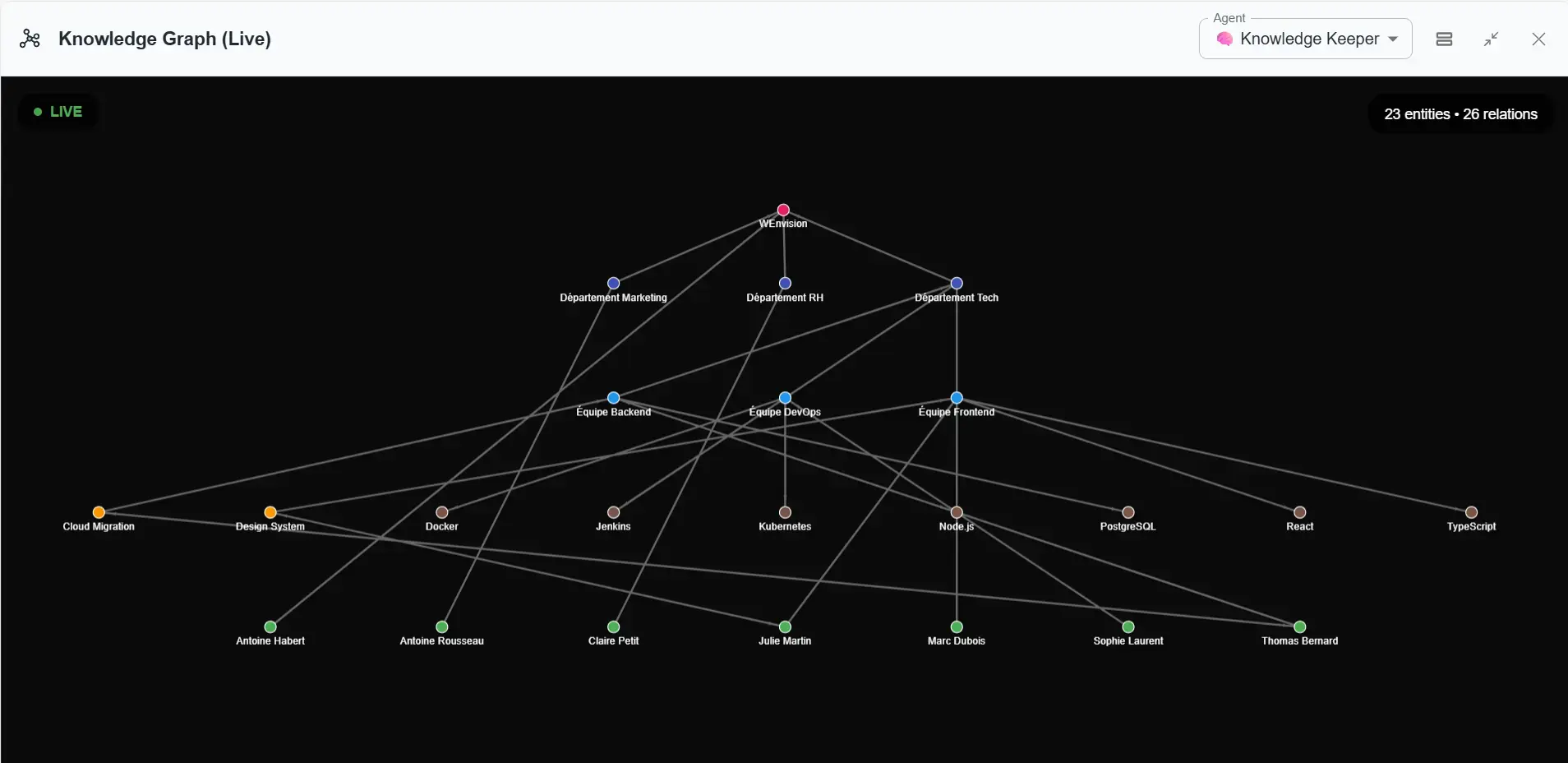
Knowledge Graph Visualization (Live): 23 entities and 26 relationships representing WEnvision's organizational structure
The Mission Strategist Graph: Mission and Workflow Vision
The Mission Strategist maintains a different graph:
- Missions: what are your objectives? What are the priorities? What are you trying to accomplish this quarter?
- Tasks: how do you break down the work? What are the sprint tasks? Who is assigned to what?
- Workflow: how do things chain together? What's your validation process? How do you move from one phase to another?
This graph evolves quickly. A project progresses, tasks are completed, new missions appear. It's dynamic memory that follows the rhythm of your activity.
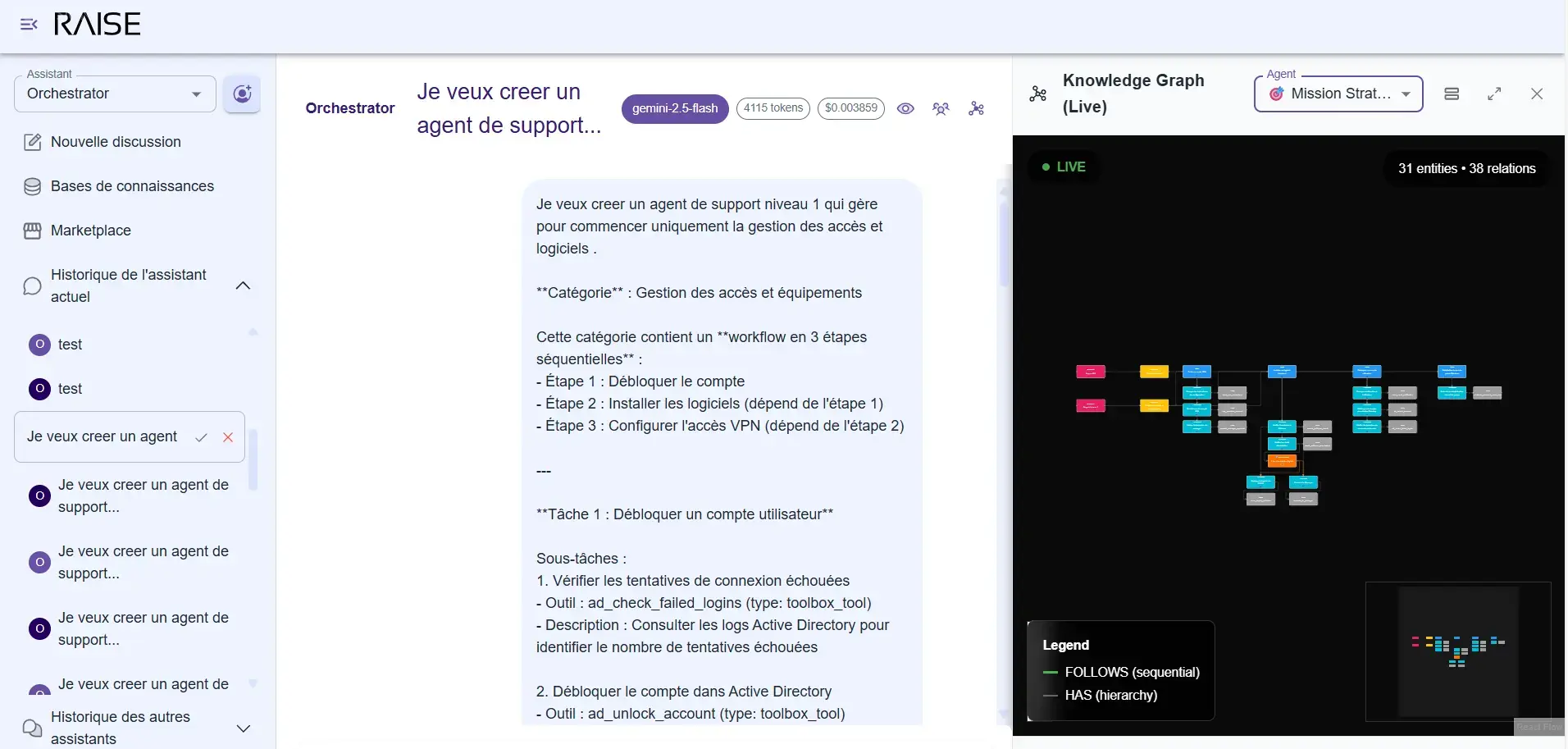
The user (administrator) defines a support mission for the adaptive agent
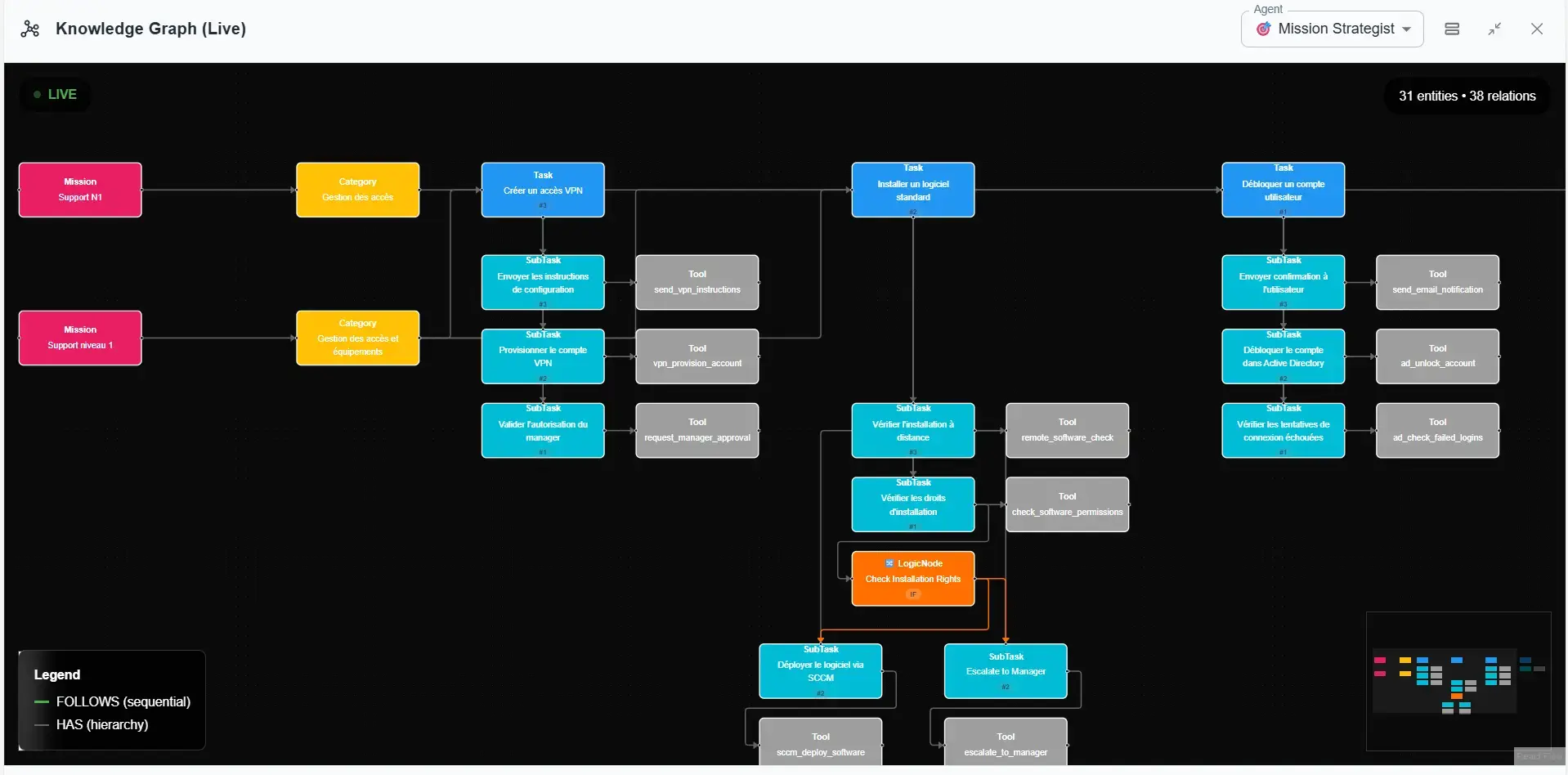
The Mission Strategist captures information and transcribes it into a process/workflow-oriented GraphRag
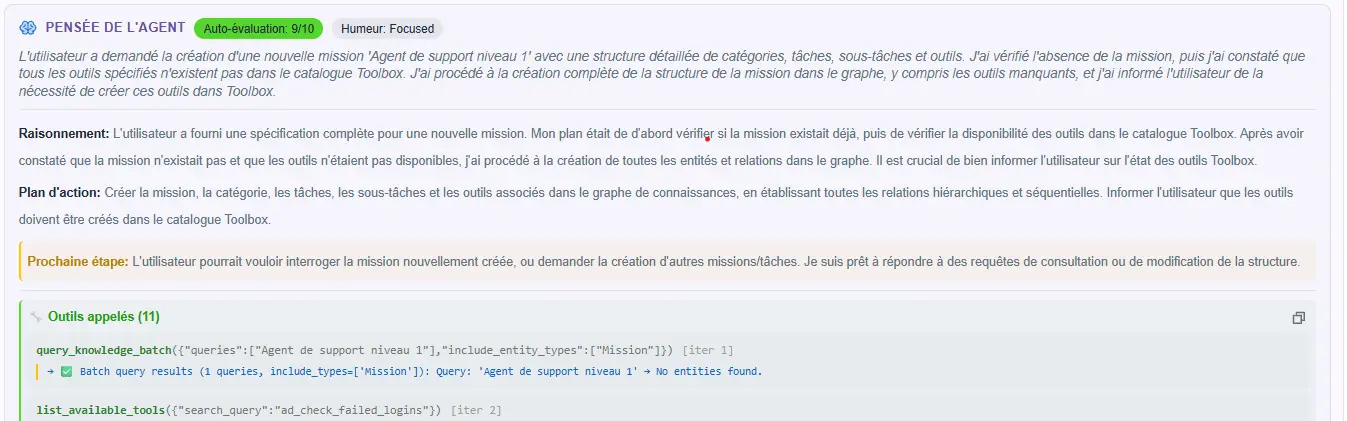
Self-observation remains essential and is enriched with information about tools used
Why Two Graphs?
Because the rhythms of evolution are different. Your organization changes slowly (a few hires per month, a reorganization per year). Your missions change quickly (new sprints, new tasks, new priorities every week).
Separating the graphs allows adapting update strategies and validation mechanisms. And most importantly, each agent can focus on a structure optimized for its role.
End of Part 1. Find the continuation of this article in Part 2.
Continue Your Exploration
Discover other articles in the Adaptive Agentic Systems cluster within the AI universe