
Piloter vos agents IA avec vos outils existants : le quick win du ticketing
La double injonction de l'agentique
Quand on se lance dans l'agentique, on fait face à deux injonctions contradictoires.
D'un côté, la voix de la raison : "On ne veut pas faire n'importe quoi. Il nous faut de l'observabilité, de la gouvernance, une stratégie long terme. On ne va pas mettre des agents en production sans savoir comment les piloter."
De l'autre, la réalité du terrain : "On ne peut pas attendre six mois pour lancer un premier agent. On a besoin de manipuler, de confronter les use cases au réel, de faire mûrir nos idées par la pratique."
Les deux camps ont raison. Et c'est bien ça le problème.
Attendre d'avoir tout construit, c'est la paralysie. Foncer sans cadre, c'est la dette technique assurée et la perte de contrôle à moyen terme.
Il existe pourtant un chemin du milieu. Et il passe probablement par un outil que vous avez déjà.
Deux piliers non-négociables
Avant de parler d'outillage, rappelons ce qui rend un système agentique pilotable. Dans notre approche de l'agentique adaptative, deux piliers sont incontournables.
L'auto-observabilité
Un agent qui ne sait pas expliquer ce qu'il fait est une boîte noire. Et une boîte noire, on ne peut ni la debugger, ni l'améliorer, ni lui faire confiance.
L'auto-observabilité, c'est la capacité de l'agent à exposer son propre raisonnement. Pas juste sa réponse finale, mais le chemin qu'il a pris pour y arriver. Ce qu'il a compris de la demande. Les hypothèses qu'il a posées. Les alternatives qu'il a écartées. Les zones où il était incertain.
Ces traces cognitives, le terme qu'on utilise pour désigner ces métadonnées de raisonnement, sont ce qui transforme un agent opaque en agent auditable. Sans ça, vous êtes condamné à itérer à l'aveugle, en croisant les doigts pour que ça marche mieux.
Le human in the middle
L'autonomie totale d'un agent, c'est un horizon. Pas un point de départ.
Un agent en production doit pouvoir solliciter l'humain quand c'est nécessaire. Pas comme un aveu d'échec, mais comme une mécanique normale de fonctionnement. L'agent doute ? Il escalade. La situation est ambiguë ? Il demande une validation. Le cas est nouveau ? Il signale et attend.
Cette supervision n'est pas figée. Elle évolue avec la maturité du système. Au début, on vérifie beaucoup. Puis on délègue les cas simples. Puis on ne supervise plus que les exceptions. L'humain passe progressivement de "vérifier" à "arbitrer" à "auditer".
Mais pour que cette évolution soit possible, il faut un cadre. Un système qui trace les escalades, qui permet la relecture, qui mesure la pertinence des interventions humaines.
Le problème : ces piliers demandent de l'outillage
Voilà le hic. L'auto-observabilité et le human in the middle ne sont pas juste des principes théoriques. Ils nécessitent une infrastructure concrète :
- Un endroit où stocker les traces de raisonnement
- Un mécanisme d'escalade et de notification
- Un moyen de relire et d'analyser les traitements
- Des dashboards pour piloter la qualité
Et quand on démarre, cette infrastructure n'existe pas. On peut la construire from scratch, mais ça prend du temps, du budget, des compétences. On peut acheter une plateforme dédiée, mais c'est un engagement lourd avant même d'avoir validé ses use cases.
Ou alors, on peut regarder ce qu'on a déjà sous la main.
L'agent IA : ni tout à fait API, ni tout à fait humain
C'est là qu'on touche à un paradoxe intéressant. Un agent IA doit être piloté sur deux axes qui n'ont traditionnellement rien à voir.
L'axe technique. Temps de réponse, consommation de tokens, taux d'erreur, coût par requête. Du monitoring classique. Vos outils APM savent faire : Datadog, Grafana, ce que vous voulez.
L'axe qualitatif. Est-ce que l'agent a bien compris la demande ? Sa réponse était-elle pertinente ? A-t-il escaladé au bon moment ? Aurait-il dû demander une clarification plutôt que foncer ?
Ce deuxième axe, c'est précisément là où se jouent l'auto-observabilité et le human in the middle. Et aucun outil technique classique ne sait le gérer. Parce que ce n'est pas une métrique. C'est un jugement.
Or ce jugement, dans les organisations, on sait déjà le porter. On le fait tous les jours pour les équipes humaines. On vérifie le travail, on identifie les patterns, on ajuste les process, on forme les gens.
Les outils de ticketing (Jira, Zendesk, ServiceNow) ont été construits exactement pour ça. Tracer des demandes, suivre leur traitement, mesurer la qualité, gérer les escalades, faire monter en compétence.
L'idée devient évidente : si un agent IA doit être piloté comme un collaborateur, pourquoi ne pas utiliser les mêmes outils qu'on utilise pour piloter des collaborateurs ?
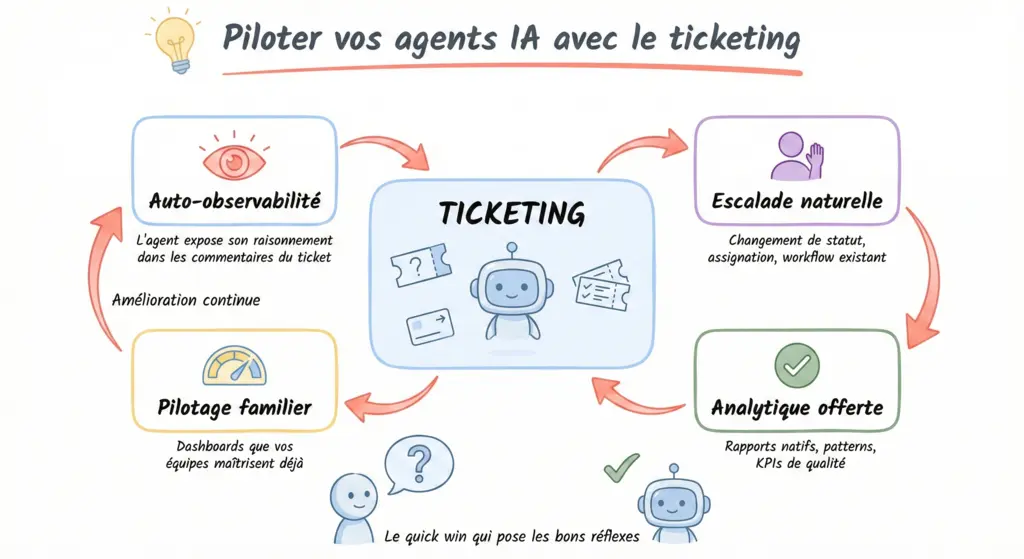
Le ticketing comme socle de pilotage
Connecter votre agent à votre système de ticketing, ce n'est pas un bricolage. C'est une architecture légère qui répond directement aux exigences de l'agentique adaptative.
Et techniquement, c'est devenu très simple. Les éditeurs proposent généralement un MCP (Model Context Protocol) pour faciliter l'intégration avec les agents IA. Sinon, vous pouvez développer vos propres outils : ces solutions sont fortement APIsées, avec un CRUD complet sur les tickets, les statuts et les commentaires.
1. Les traces cognitives deviennent lisibles
Dans l'agentique adaptative, l'auto-observation est clé. L'agent doit exposer son raisonnement : ce qu'il a compris, les hypothèses qu'il pose, les zones où il est incertain.
Ces traces cognitives, vous pouvez les stocker en commentaires dans le fil de discussion du ticket. Ça crée une trace lisible par n'importe qui, pas besoin d'être développeur pour comprendre ce qui s'est passé.
C'est auditable. C'est explicable. C'est exactement ce qu'on attendrait d'un humain qui documente son travail.
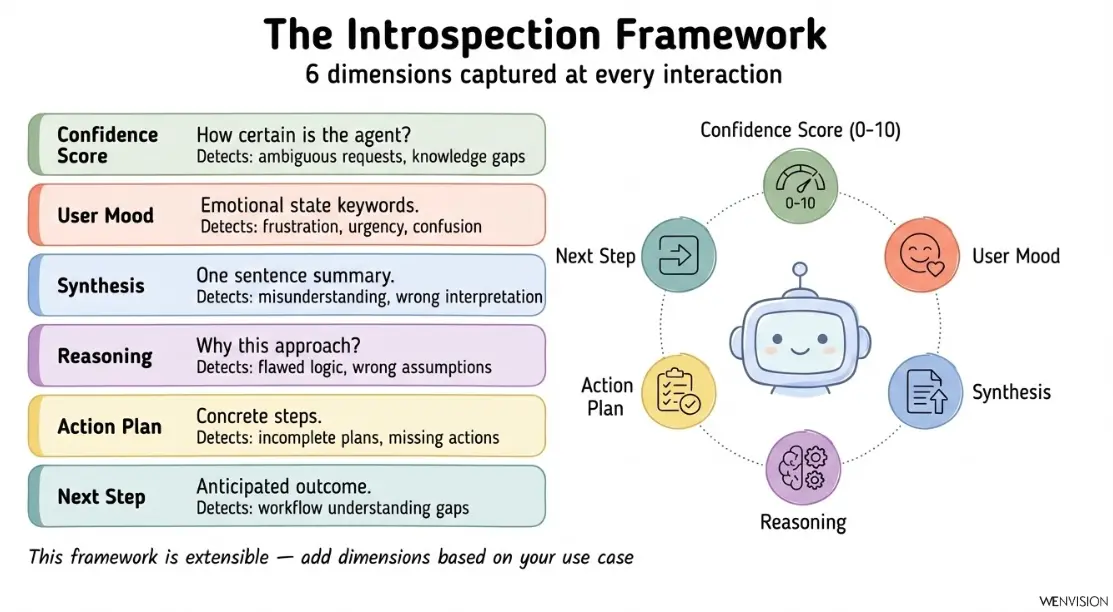
Et vous pouvez aller plus loin : certaines traces peuvent être mappées sur des champs custom du ticket (score de confiance, catégorie de demande, user mood). Ça ouvre la porte au reporting structuré : ces champs deviennent des axes d'analyse dans vos dashboards natifs, des filtres pour vos vues, des KPI pour vos revues hebdo.
Les traces cognitives vont aussi au-delà du raisonnement technique. Elles capturent le user mood : frustration, urgence, confusion. Ces signaux émotionnels, détectés à chaque interaction, sont une métadonnée précieuse pour piloter la qualité de service.
2. Le feedback utilisateur devient actionnable
Les systèmes de ticketing ont déjà des mécaniques de feedback : pouce en l'air, pouce en bas, notation. Mais soyons honnêtes, on sait comment ça se passe. Les utilisateurs ne les utilisent que quand ça ne marche pas.
Avec un agent, vous pouvez faire mieux. En phase de résolution, l'agent peut solliciter activement l'avis de l'utilisateur, et lui montrer que ce retour compte vraiment. "Votre avis m'aide à m'améliorer" n'est plus une formule creuse quand c'est effectivement le cas.
Combiné au user mood capté automatiquement, vous obtenez une boucle d'amélioration continue bien plus riche que le feedback passif qu'on collecte et qu'on oublie.
3. L'escalade devient naturelle
Le "human in the middle", c'est souvent le point de friction dans les architectures agentiques. Comment l'agent demande-t-il de l'aide ? Comment notifie-t-il qu'il a besoin d'une validation ?
Les outils de ticketing ont résolu ce problème depuis des années. Changement de statut, assignation à un autre groupe, tag "besoin validation", notification automatique.
Votre agent ne sait pas quoi faire ? Il escalade. Le ticket tombe dans la queue de quelqu'un qui sait. Pas besoin d'inventer un système custom. Le workflow existe déjà.
4. L'analytique est offerte*
* Selon votre solution et votre appétence aux négociations commerciales.
Jira a Rovo. Zendesk a ses rapports natifs. ServiceNow a des capacités d'analytics puissantes.
Ces outils peuvent analyser les traitements de votre agent comme ils analysent ceux de vos équipes humaines :
- Quels types de demandes génèrent le plus d'escalades ?
- Quel est le temps moyen de résolution par catégorie ?
- Combien d'échanges avant de clore un ticket ?
- Les escalades étaient-elles justifiées ?
Vous pouvez même utiliser les agents analytiques natifs de ces plateformes pour faire du reporting conversationnel sur la performance de vos agents IA. C'est de la méta-agentique, et c'est gratuit.
Hum...
Bon. Pour être plus précis : sûrement déjà en place ! Et c'est tout l'intérêt !
5. Le multilingue devient trivial
Voilà un problème que personne n'anticipe au démarrage : votre agent parle à des utilisateurs en français, en espagnol, en allemand. C'est naturel pour lui, les LLM sont nativement multilingues. Mais votre équipe de supervision, elle, ne l'est pas forcément.
Si les traces de raisonnement sont dans la langue de l'utilisateur, vous vous retrouvez avec un reporting fragmenté, des dashboards illisibles, et des superviseurs qui ne peuvent analyser qu'une fraction des tickets.
La solution est élégante : l'agent répond à l'utilisateur dans sa langue, mais rédige ses traces cognitives systématiquement en anglais. La conversation reste naturelle pour l'utilisateur. Les métadonnées d'observation restent uniformes pour l'analyse.
Résultat : votre BI fonctionne sur un corpus homogène. Vos catégorisations sont cohérentes. Vos superviseurs à Paris peuvent auditer un ticket traité en portugais. Et vos rapports agrègent des données comparables, quelle que soit la langue d'origine.
C'est un de ces détails d'architecture qui semble anodin, mais qui fait la différence entre un système qui scale et un système qui s'effondre dès qu'on sort du marché domestique.
6. La gouvernance arrive sans effort
C'est peut-être le bénéfice le plus sous-estimé. En utilisant le ticketing, vous héritez automatiquement de tout l'écosystème de gouvernance qui va avec.
Qui peut valider les décisions de l'agent ? Vos règles d'assignation répondent déjà à cette question. Combien de temps peut-on laisser un ticket en escalade sans action ? Vos SLA existants s'appliquent. Faut-il une trace pour les auditeurs ? Elle existe, horodatée, dans un système que votre DSI connaît et approuve.
Vous n'avez pas à convaincre la sécurité, la compliance ou le management qu'un nouvel outil obscur est fiable. L'agent s'insère dans un cadre déjà validé. C'est une conversation en moins, et souvent, c'est celle qui bloque tout.
Un scénario concret : l'agent de support IT
Prenons un cas simple. Vous déployez un agent qui traite les demandes de support IT de niveau 1.
9h12, un ticket arrive : "Je n'arrive plus à me connecter au VPN depuis ce matin."
L'agent analyse. Il poste un premier commentaire interne :
{
"confidence_score": 7.5,
"user_mood": "neutral",
"synthesis": "Isolated VPN incident, Marketing user with no recent history",
"reasoning": "No VPN incident in 6 months → likely corrupted local config or expired certificate",
"action_plan": "Standard VPN reset procedure + documentation link",
"next_step": "Await user feedback to confirm resolution"
}9h13, l'agent répond à Marie :
"Bonjour Marie, je comprends que vous ne parvenez plus à vous connecter au VPN. Ce type de problème est souvent lié à la configuration locale. Voici la procédure de reset à suivre : [lien documentation]. N'hésitez pas à me tenir informé si le problème persiste."
9h47, Marie répond : "J'ai suivi la procédure mais ça ne marche toujours pas. Et en fait, mes collègues ont le même problème."
L'agent analyse à nouveau. Nouveau commentaire :
{
"confidence_score": 3.0,
"user_mood": "frustrated",
"mood_signals": ["still not working", "repeated failure"],
"synthesis": "Collective incident detected → local issue hypothesis invalidated",
"reasoning": "Multiple users affected = likely infrastructure incident",
"action_plan": "Immediate escalation to Network Infra team",
"next_step": "Notify infra team + inform user of escalation"
}9h48, l'agent informe Marie et escalade :
"Marie, merci pour ces précisions. Le fait que vos collègues soient également touchés indique un problème plus large que je ne peux pas résoudre seul. Je transfère immédiatement votre ticket à l'équipe Infrastructure Réseau qui pourra intervenir. Vous serez tenue informée de l'avancement."
Le ticket passe automatiquement en statut "Escaladé", assigné au groupe "Infra Réseau", avec une notification Slack.
10h15, l'équipe infra identifie un problème de certificat côté serveur. Résolution en cours.
10h45, incident résolu. L'agent envoie un message à Marie : "Le problème de VPN est résolu. Votre retour m'aide à m'améliorer, n'hésitez pas à noter cette interaction." Le ticket est clos avec un tag "Escalade justifiée, incident infra".
Qu'est-ce qu'on a ici ? Un agent qui documente son raisonnement à chaque étape via ses traces cognitives. Une escalade propre quand la situation dépasse ses compétences. Une trace complète pour l'analyse post-mortem. Et tout ça dans Jira, Zendesk ou ServiceNow, pas dans un système parallèle que personne ne consulte.
Le vendredi suivant, le manager peut sortir un rapport : "Cette semaine, l'agent a traité 847 tickets. 12% d'escalades, dont 89% jugées pertinentes. Temps moyen de résolution autonome : 8 minutes. 18% des tickets avec frustration détectée, en baisse de 3 points. Point d'attention : les demandes VPN ont un taux d'escalade anormalement haut, à investiguer."
C'est du pilotage. Avec des outils que tout le monde connaît.
Un quick win qui pose les bons réflexes
Ce serait une erreur de voir cette approche comme un simple hack temporaire, un bricolage en attendant mieux.
En réalité, utiliser le ticketing dès le départ vous force à structurer votre pensée :
- Qu'est-ce qu'une escalade appropriée pour cet agent ?
- Quels SLA sont raisonnables ?
- Quels KPI reflètent vraiment la qualité du service ?
- Qui supervise, et à quelle fréquence ?
Ces questions, vous devrez y répondre tôt ou tard. Autant le faire dès le premier agent, dans un cadre qui vous guide naturellement vers les bonnes pratiques.
Et pendant ce temps, vous accumulez de la donnée. Des vrais tickets, des vraies escalades, des vrais patterns. Quand vous aurez le budget ou le besoin d'une solution dédiée, vous saurez exactement ce qu'il vous faut. Vous aurez les specs, écrites par l'usage.
Le quick win devient fondation.
Au-delà du support : le principe s'étend à tous les métiers
L'exemple du support IT est parlant parce que le ticketing y est omniprésent. Mais ce serait réducteur de cantonner cette approche aux métiers des opérations.
Le principe fondamental reste le même : un agent doit être proche de la donnée et de la connaissance, mais aussi proche des outils que les équipes utilisent au quotidien. Quel que soit le métier.

Équipes de développement
Votre équipe build travaille en cycle agile avec Azure DevOps, GitHub Projects ou GitLab ? L'agent peut s'intégrer dans ce workflow exactement de la même manière. Il crée des epics, décompose en user stories, déplace des tâches dans le Kanban, documente ses décisions dans les commentaires.
Les traces cognitives se retrouvent dans la description des tâches ou en commentaires. Les escalades passent par un changement de statut ou une mention @équipe. Le human in the middle se fait naturellement via les reviews de pull requests ou les validations de stories.
Le manager technique a le même niveau de visibilité que dans notre exemple IT : combien de tâches l'agent a-t-il générées cette semaine ? Quel pourcentage a nécessité une reformulation ? Quels types de demandes génèrent le plus de friction ?
Équipes marketing et projets
Une équipe marketing qui pilote ses campagnes dans Monday.com, Asana, Notion ou Trello peut appliquer exactement la même logique. L'agent devient un membre de l'équipe qui documente son travail, sollicite des validations et rend compte de son activité dans l'outil que tout le monde utilise déjà.
Besoin de générer des briefs créatifs ? L'agent crée une tâche avec son raisonnement en commentaire. Incertain sur le ton à adopter ? Il escalade vers le responsable éditorial. Résultats de campagne à analyser ? Il synthétise et poste ses conclusions dans le fil du projet.
L'analytique native de ces plateformes fait le reste : qui produit quoi, à quel rythme, avec quelle qualité.
Le dénominateur commun
Que vous utilisiez des tickets, des user stories, des tâches ou des cartes Kanban, la mécanique est identique :
- Traçabilité : l'agent documente son raisonnement dans l'outil métier
- Escalade : il utilise les workflows existants pour solliciter l'humain
- Supervision : le management pilote via les dashboards qu'il connaît déjà
- Gouvernance : les règles d'accès et de validation préexistantes s'appliquent
L'agentique adaptative ne demande pas de réinventer vos process. Elle demande d'y intégrer un nouveau type de collaborateur, qui se plie aux mêmes règles que les autres.
Avec un bonus : on peut lui demander ce qu'on n'oserait pas imposer à un humain... comme documenter tout ce qu'il fait. :-)
Et sans se sentir coupable d'un futur Skynet pour autant ! Car pour un LLM, écrire un cheminement, c'est naturel : c'est ce pour quoi il est justement fait. Et ses traces peuvent même être rédigées après avoir répondu à l'utilisateur, sans ralentir l'interaction.
Réconcilier rigueur et vélocité
L'agentique adaptative repose sur plusieurs piliers non-négociables : l'auto-observabilité et ses traces cognitives, les couches de connaissances dynamiques (knowledge, mission, expérience), l'architecture multi-agents, le human in the middle évolutif. Dans cet article, nous n'en avons abordé que deux, l'auto-observabilité et le human in the middle, parce que ce sont précisément ceux que le ticketing adresse naturellement. Mais ces deux-là ne sont pas optionnels si vous voulez passer du POC à la production.
Mais ils ne nécessitent pas non plus une plateforme construite from scratch avant de pouvoir avancer.
Votre système de ticketing est déjà là. Il implémente nativement les mécaniques dont vous avez besoin : traçabilité, escalade, supervision, reporting. Il fait 80% du travail de pilotage requis pour démarrer. Et il le fait avec des outils que vos équipes maîtrisent déjà.
C'est ça, le chemin du milieu entre la paralysie du "on attend d'avoir tout bien fait" et le chaos du "on fonce sans cadre".
Vous voulez lancer votre premier agent en production avec un vrai cadre de pilotage ?
Ouvrez Jira, Azure DevOps, Trello, ou l'outil que vous utilisez déjà pour vous organiser. Branchez l'agent dessus, c'est généralement très facile. Créez un projet. Commencez.
L'outil parfait n'existe pas. L'outil que vous maîtrisez déjà, si.
Continuer votre exploration
Découvrez d'autres articles du cluster agents-systemes-agentiques dans l'univers Intelligence Artificielle