
L'agentique adaptative - Les principes d'une IA qui grandit
Comprendre les systèmes agentiques adaptatifs
L'agentique est partout. Nous en parlons, nous en faisons, nous en vendons. Mais entre les démos impressionnantes et les systèmes qui tiennent en production, il y a un gouffre que peu franchissent.
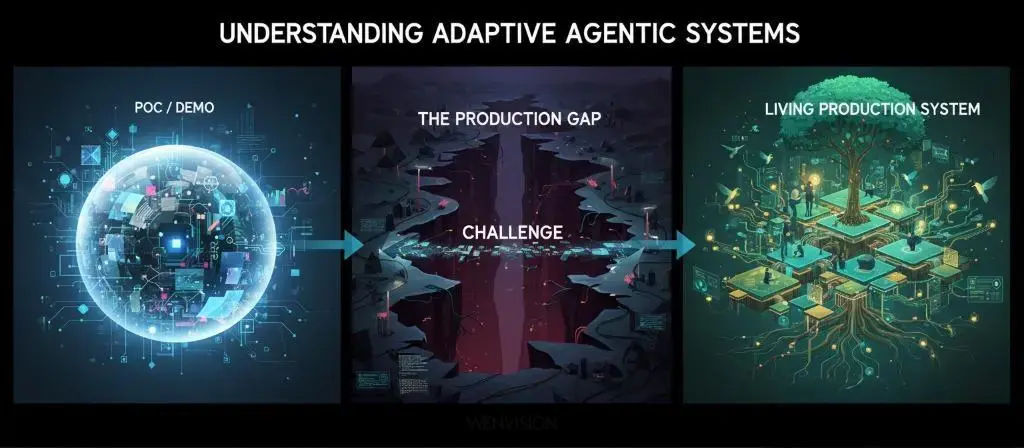
Cette série en trois parties explore ce gouffre, et comment le traverser.
Partie 1 - L'agentique qui "marche presque" ne marche pas
Nous posons les fondations conceptuelles. Pourquoi l'agentique actuelle passe difficilement du POC à la production, quels sont les pièges systématiques, et sur quels principes construire pour les éviter. Le problème n'est pas que ça plante, c'est que cela marche "à peu près", et pour arriver à l'étape de la production, cela n'atteint pas le niveau de fiabilité voulu. Et surtout, nous ne savons pas comment l'améliorer parce que nous n'avons pas outillé le système pour ça dès le départ.
Partie 2 - L'agentique adaptative : les principes d'une IA qui grandit
Nous passons à la vision. Les principes de l'agentique adaptative, comment construire des systèmes qui ne se contentent pas d'exécuter mais qui observent, apprennent, et grandissent. Nous explorons les piliers architecturaux qui rendent cette vision possible.
Partie 3 - Mettre l'agentique adaptative en production, illustration avec RAISE
→ Partie 3a : Architecture, conception et opérationnalisation
→ Partie 3b : Orchestration multi-agents et knowledge graph dynamique
Nous passons à l'implémentation. Comment ces principes se traduisent concrètement dans RAISE, la plateforme d'IA générative du groupe SFEIR. Quelles architectures, quels choix de design, quelles mécaniques mettre en place. Du concept à la réalité opérationnelle.
Parce qu'entre avoir raison sur le papier et faire tourner un système en production, il y a tout un monde. Et c'est précisément ce monde-là que nous allons explorer.
Dans la première partie, nous avons posé le diagnostic : l'agentique actuelle passe rarement du POC à la production, faute de fiabilité, d'observabilité et de capacité d'apprentissage.
Dans cette deuxième partie, nous explorons la vision alternative : l'agentique adaptative. Nous présentons les principes architecturaux qui permettent de construire des systèmes qui ne se contentent pas d'exécuter, mais qui observent, apprennent, évoluent. Des systèmes qui grandissent avec vous.
Un SI qui dialogue, pas qui commande
Avant d'entrer dans les détails techniques, posons la vision globale.
Chez WEnvision, nous défendons une vision claire : le système d'information du futur ne sera pas un empilement d'applications et d'interfaces. Il sera conversationnel.
Pas juste dans le sens "on parle à un chatbot". Conversationnel au sens profond : un espace où les personas humaines et artificielles dialoguent en continu pour atteindre un objectif commun. Un système qui négocie, qui clarifie, qui s'ajuste.
Le SI conversationnel, c'est l'arrivée du langage naturel dans toutes les interactions : Humain → SI, Humain → IA, et IA → IA. Des agents qui collaborent entre eux en langage naturel, des processus qui s'ajustent par le dialogue, des modèles qui négocient leurs décisions.
L'interface, le bouton, le formulaire, l'écran, ne disparaîtront pas. Mais ils cesseront d'être la condition de l'action. Ils deviendront le support d'un échange. Ce n'est plus l'utilisateur qui s'adapte au système ; c'est le système qui s'adapte à l'utilisateur.
Et ça change tout.
Parce qu'un système conversationnel n'est pas un simple assistant. C'est un partenaire cognitif. Il ne se contente pas d'exécuter une tâche. Il aide à la définir, à la clarifier, à en concevoir le processus. Il raisonne, il justifie, il apprend.
C'est ça, la vraie transformation. Pas un chatbot qui répond poliment. Mais un système qui co-construit avec vous.
Cette vision n'est pas un horizon lointain. C'est le cadre structurant dans lequel s'inscrivent aujourd'hui tous les principes que nous allons détailler maintenant.
Pour qu'un système d'information devienne réellement conversationnel, pour qu'il puisse négocier, s'ajuster, co-construire, il lui faut des fondations spécifiques :
- La capacité de s'observer pour comprendre ses propres raisonnements
- Une base cognitive qui structure le contexte (utilisateur, mission, information)
- Une mémoire organisationnelle vivante qui rend le savoir accessible et structuré
- Une architecture qui favorise la coopération plutôt que l'exécution mécanique
- Un apprentissage supervisé qui fait grandir le système
Explorons maintenant ces fondations, une par une.
Auto-observabilité et supervision qualité intelligente
Pour qu'un système apprenne, il faut d'abord pouvoir voir comment il raisonne. Pas juste ce qu'il répond, mais pourquoi il répond ça, quelles hypothèses il pose, quelles zones le rendent incertain.
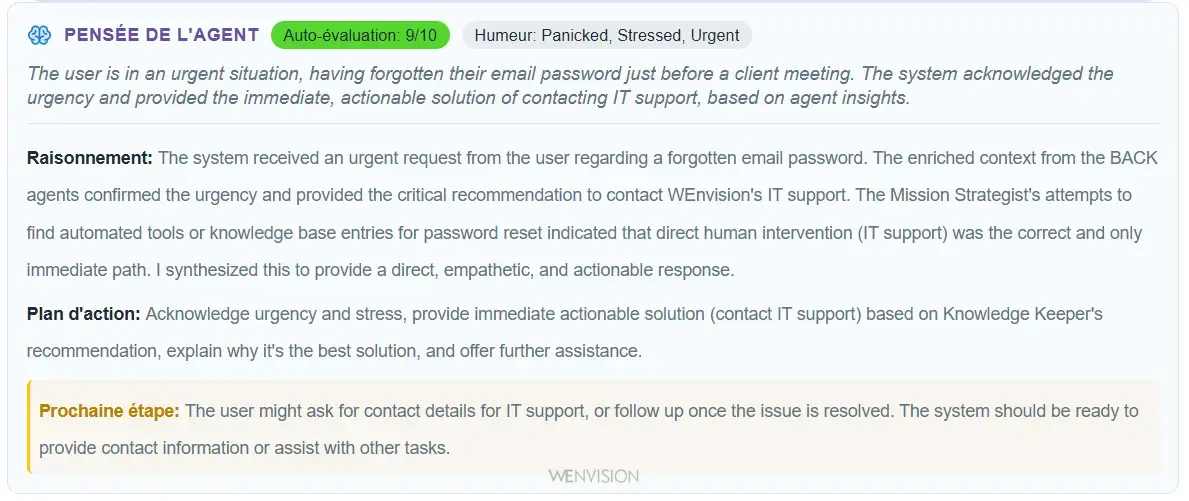
Exemple d'auto-observabilité : le système expose sa pensée, son raisonnement et son plan d'action
C'est le premier principe, et peut-être le plus crucial : l'auto-observabilité.
Pourquoi l'observabilité est la condition de tout
Sans observabilité, vous êtes aveugle. Vous ne savez pas si votre prompt fonctionne bien, vous ne détectez pas les dégradations, vous ne comprenez pas pourquoi un cas passe et un autre échoue. Vous êtes dépendant de ce que vous pouvez deviner de la réponse de l’IA.
Vous itérez à l'aveugle, en croisant les doigts.
Un exemple concret vécu
Nous avions en phase exploratoire un LLM qui répondait normalement aux utilisateurs. Rien d'anormal en surface. Mais en analysant les traces d'observation, nous avons remarqué que le modèle écrivait dans son raisonnement interne : "l'utilisateur me demande 2 fois...".
En creusant, nous avons rapidement découvert un bug dans notre implémentation LangGraph qui envoyait deux fois les inputs utilisateur au LLM. Sans l'auto-observabilité, ce problème serait resté totalement transparent pour nous, créant une consommation inutile de tokens et une possible confusion dans le raisonnement du modèle.
Le système nous a lui-même révélé son propre dysfonctionnement immédiatement.
Supervision qualité intelligente : au-delà des dashboards
Mais l'auto-observabilité seule ne suffit pas. Il faut aussi un système qui évalue la qualité, qui détecte les dégradations, qui identifie les patterns problématiques.
Plutôt que de deviner si un changement de prompt améliore ou dégrade le système, on mesure. On utilise un agent dédié qui analyse les conversations, identifie les problèmes récurrents, et recommande des améliorations précises. Pas "le système marche moins bien", mais "l'agent demande trop de clarifications parce que le prompt manque d'orientation sur quand agir".
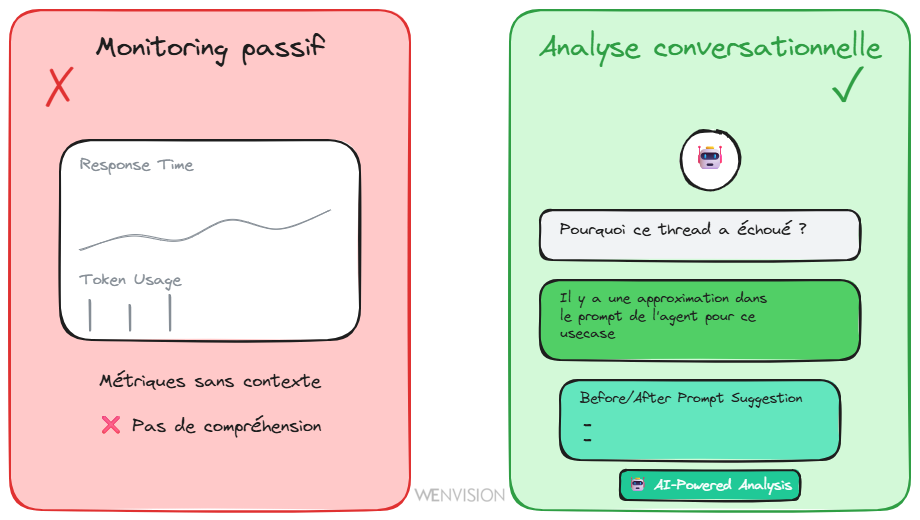
Monitoring passif (métriques sans contexte) vs Analyse conversationnelle (dialogue avec l'agent de qualité)
Pilotage conversationnel de la qualité par IA. Vous ne consultez pas juste un dashboard avec des métriques. Vous dialoguez avec l'agent de qualité :
- "Pourquoi ce thread a mal tourné ?"
- "Quelles améliorations suggères-tu pour ce type de cas ?"
- "Compare les deux versions de prompt"
Le système évalue la qualité de ses propres sorties, détecte les incohérences, signale les zones de faible confiance. Il peut même suggérer des modifications de prompt, avec un avant/après et une estimation d'impact.
Sans cette capacité à s'observer et à s'évaluer, aucun apprentissage n'est possible.
Les trois piliers d'un système qui apprend
Un système adaptatif ne s'écrit pas comme un programme. Il s'entraîne comme un organisme.
Et pour cela, il repose sur trois fondations qui constituent sa base cognitive :
1. Le contexte utilisateur
Comprendre qui agit : l'intention, les contraintes, le rôle, le niveau d'autonomie attendu. Pas juste un username dans une base, mais une vraie compréhension de ce que la personne cherche à accomplir.
Pourquoi c'est essentiel ? Parce qu'une même action ("créer un client") n'a pas le même sens selon qu'elle vient d'un commercial qui prospecte, d'un chef de projet qui monte une équipe, ou d'un comptable qui régularise une facturation. Sans contexte utilisateur, le système répond de manière générique, là où il devrait s'adapter au besoin réel.
2. Le contexte de mission
Définir pourquoi on agit. Pas seulement la liste des étapes à suivre, mais le sens du résultat.
Ce n'est pas la même chose de "réinitialiser un mot de passe parce que l'utilisateur l'a oublié" et de "réinitialiser un mot de passe parce qu'il apparaît dans un leak". De la même façon, "changer l'adresse d'un client parce qu'il y a eu une erreur de saisie" ne nécessite pas les mêmes actions que "changer l'adresse d'un client parce qu'il a déménagé".
Pourquoi c'est essentiel ? Parce que comprendre l'intention derrière l'action permet au système de prendre les bonnes décisions quand il rencontre une situation imprévue.
Si le mot de passe apparaît dans un leak, le système doit forcer le changement immédiat, vérifier les connexions récentes, alerter la sécurité. Si l'utilisateur l'a simplement oublié, suivre le processus standard suffit.
Si un client a déménagé, il faut mettre à jour l'adresse de facturation, l'adresse de livraison, potentiellement changer de filiale commerciale. Si c'est une correction d'erreur de saisie, on corrige juste l'adresse sans toucher au reste.
Sans contexte de mission, le système applique mécaniquement des règles, là où il devrait faire preuve de jugement.
3. La modélisation de l'information
Rendre les connaissances accessibles, liées, interprétables. Si vos données sont enfouies dans des silos, le LLM va chercher. S'il doit chercher, il va ralentir. S'il ralentit, l'utilisateur va abandonner.
Un graphe de connaissance bien structuré permet au modèle de raisonner plutôt que de chercher. C'est comme la différence entre mémoriser par cœur et comprendre les liens entre les concepts.
Ces trois couches (utilisateur, mission, information) constituent la base cognitive du système. Elles permettent au LLM de relier les actions à une intention, d'ajuster sa stratégie, de créer des plans cohérents sans qu'ils aient été programmés.
Mais comment structurer et maintenir cette base cognitive ? C'est là qu'intervient le GraphRAG dynamique.
La mémoire cognitive : GraphRAG dynamique
Un système qui apprend a besoin d'une mémoire. Pas juste une base de données, mais une structure de connaissance qui modélise l'organisation, les processus, les relations. Une mémoire qui peut être interrogée, enrichie, comprise par le LLM.
C'est le rôle des graphes de connaissance.
Le graphe comme socle cognitif
Pour être fiable, un système agentique doit rester observable, mesurable et perfectible. Le graphe structure la mémoire du système (les entités, les relations, les décisions) dans une forme que le LLM peut comprendre, interroger et enrichir.
Le graphe devient la mémoire organisationnelle :
- Il relie les faits, les acteurs et les processus
- Il rend les décisions traçables
- Il permet d'apprendre des interactions passées
Et autour de cette base, s'installe une boucle vertueuse : Observer → Analyser → Ajuster → Ré-entraîner
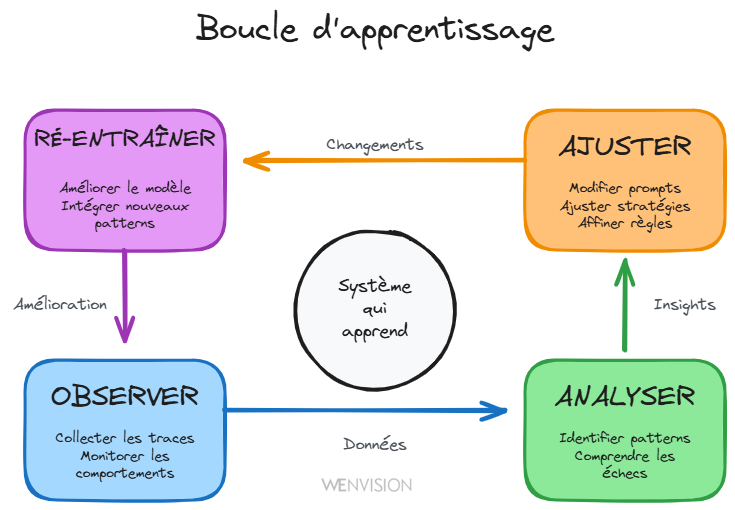
La boucle d'apprentissage continu : observer, analyser, ajuster, ré-entraîner
C'est cette boucle qui transforme un système d'agents en système d'apprentissage. Sans elle, vous avez juste une belle mécanique. Avec elle, vous avez un organisme qui évolue.
Un exemple de la puissance du graphe
Prenons un cas concret : un agent de support IT qui traite des demandes d'assistance.
Grâce au graphe organisationnel qui a reproduit l'organigramme de la boîte, le système peut identifier que 60% des problèmes remontés proviennent de la même équipe et concernent le même type de dysfonctionnement (par exemple, des problèmes d'accès VPN récurrents).
Plutôt que de traiter chaque ticket individuellement, le système peut escalader le sujet au niveau du manager : "12 personnes de votre équipe rencontrent le même problème. Il y a probablement une cause systémique à adresser."
Sans le graphe, chaque ticket est traité en silo. Avec le graphe, le système voit les patterns organisationnels et peut proposer des solutions au bon niveau.
Co-construction dynamique
Ces bases “graphes” ne peuvent pas être figées, construites une fois pour toutes.
Elles doivent être co-construites : le LLM décide de ce qui mérite d'être structuré, l'humain arbitre et valide. Itération après itération, le graphe devient de plus en plus fidèle à la réalité.
Ce n'est pas un schéma statique. C'est un organisme qui évolue avec vous.
Le graphe permet ainsi de structurer et de maintenir vivants les trois piliers de la base cognitive (contexte utilisateur, mission, information) que nous venons de détailler. Mais comment le système utilise-t-il concrètement cette mémoire structurée pour raisonner et agir ? C'est là qu'intervient l'architecture multi-agents.
Architecture multi-agents adaptative
Maintenant que nous avons posé l'observabilité (comment nous voyons) et la mémoire (ce que nous savons), explorons l'architecture : comment le système raisonne et agit.
Coopération vs juxtaposition
La plupart des architectures actuelles confondent multi-agent et multi-processus.
Nous créons plusieurs agents. Chacun a sa tâche. Ils s'exécutent en parallèle ou en séquence. Nous les relions avec des conditions. Et nous appelons ça "multi-agent".
Mais est-ce que ces agents collaborent vraiment ? Est-ce qu'ils partagent une vision commune ? Est-ce qu'ils se consultent, se corrigent, fusionnent leur raisonnement ?
Ou est-ce qu'ils sont juste plusieurs "esprits" qui s'ignorent ?
Dans un système agentique adaptatif, les agents ne sont pas simplement parallèles. Ils sont interdépendants et contextuels. L'un peut solliciter l'autre. L'un peut remettre en question le raisonnement de l'autre. Ils peuvent converger vers une décision collective qui n'existait pas dans leur logique individuelle, ou solliciter l’humain quand cela est nécessaire.
L'objectif n'est plus la coordination, mais la coopération cognitive.
Et parfois, point très important, un seul agent bien conçu (capable de jouer plusieurs rôles internes selon le contexte) vaut mieux qu'une armée d'exécutants isolés.
Agents parallèles : reproduire la cognition humaine
Quand vous abordez un problème complexe, vous faites naturellement trois choses en même temps : vous contextualisez (qui, quoi, où, comment ça fonctionne ici), vous alignez cela avec une mission (quel est mon rôle, qu'est-ce qu'on attend de moi, y a-t-il un process pour ça) et votre expérience (qu’ai je fait dans un cas similaire ou approchant, quelles sont les erreurs ou les succès passés en rapport avec cette demande).
Ces trois dimensions ne sont pas séquentielles. Elles sont parallèles.
Une architecture multi-agent peut reproduire ça : des agents spécialisés qui analysent l'input en parallèle (contexte organisationnel d'un côté, alignement stratégique de l'autre), puis une synthèse qui produit une réponse qui comprend et qui sait, pour un agent qui lui répond frontalement à l’utilisateur.
Ce n'est pas compliqué par plaisir. C'est une architecture qui mime notre façon naturelle de raisonner. Et ce que nous cherchons avec l'agentique c’est précisément cela: ne pas créer une “API magique”, un programme, mais un véritable collaborateur intelligent.
Workflow adaptatif : trigger on demand vs orchestration rigide
Si vos agents contextualisent en parallèle, vous n'avez pas besoin de tout orchestrer à l'avance. Le système peut décider d'appeler un sous-agent quand c'est pertinent, pas parce que c'est câblé dans un workflow.
Et ces agents ne fonctionnent pas uniquement en mode API (input/output). Ils peuvent avoir un vrai dialogue entre eux. Un agent peut interroger un autre agent, clarifier, négocier, itérer. C'est de la collaboration, pas de la simple transmission de données.
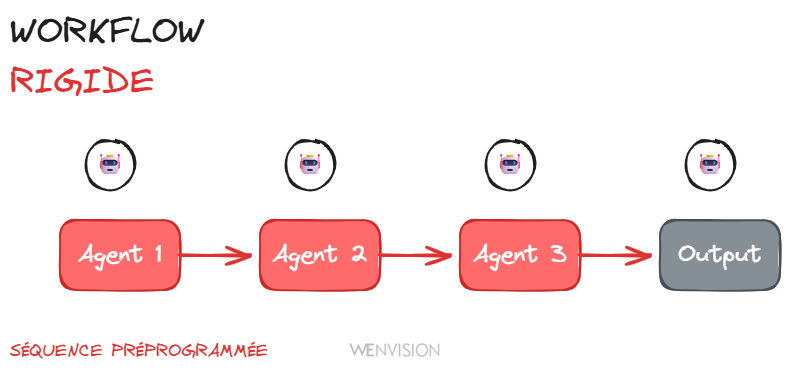
Workflow rigide : orchestration séquentielle et prédéfinie
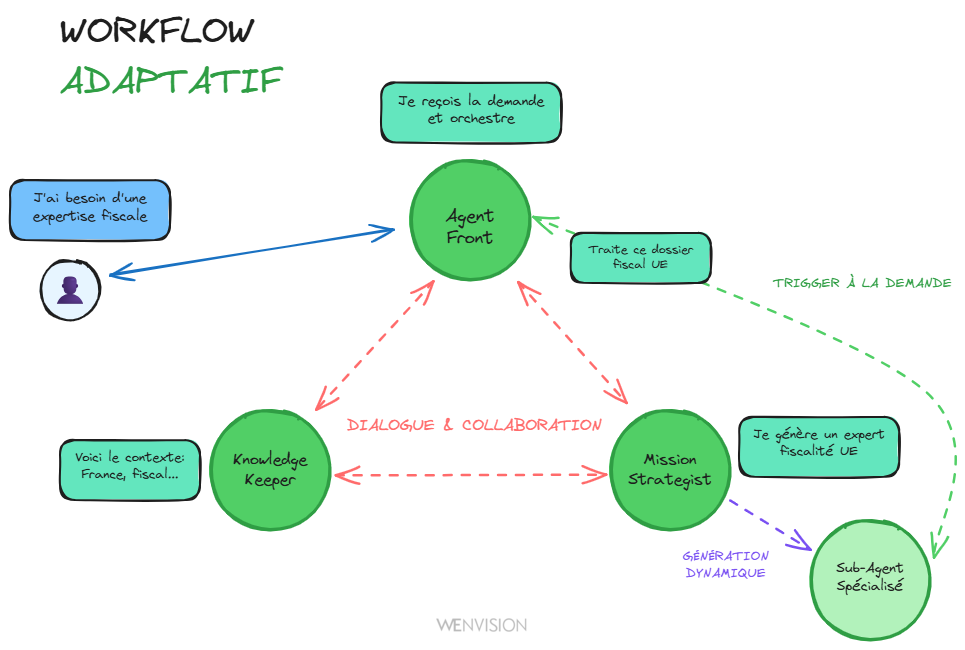
Workflow dynamique : agents qui dialoguent et s'adaptent en fonction du contexte
Génération dynamique de sous-agents
Plus fort encore : le système peut générer lui-même des sous-agents spécialisés, adaptés au contexte et à la mission du moment. Besoin d'analyser un type de document spécifique ? Besoin d'une expertise pointue sur un domaine particulier ? Le système crée l'agent dont il a besoin, avec le bon prompt, les bons outils, le bon périmètre.
Ce n'est pas du chaos. C'est de l'adaptativité guidée.
Les agents établissent le cadre. Le système décide de la tactique. Et l'humain supervise la trajectoire.
Trajectoire vers l'autonomie : les stades de maturité
L'autonomie totale, c'est un horizon. Pas une étape immédiate.
Un système agentique traverse, comme un être vivant, plusieurs stades de maturité :
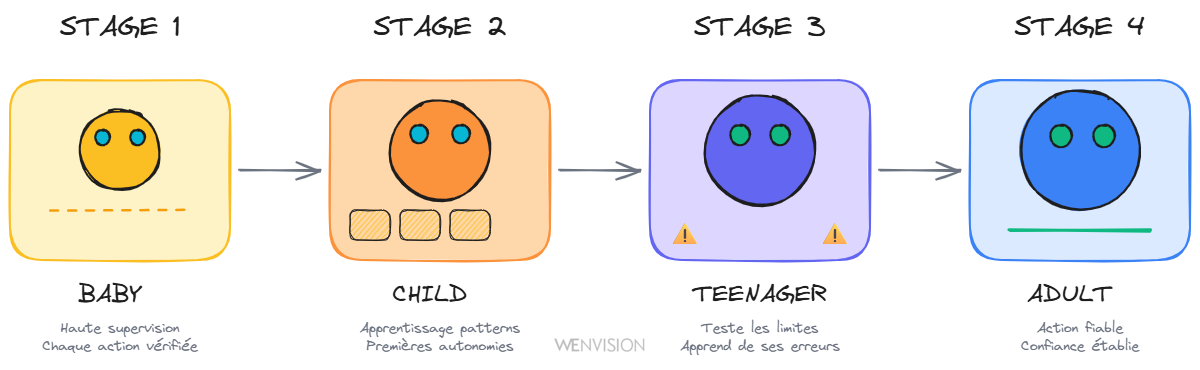
Les 4 stades de maturité : Baby (supervision totale), Child (apprentissage de patterns), Teenager (test des limites), Adult (action fiable)
La conception
Avant tout, comme pour un enfant, il faut le concevoir ;-)
Et contrairement à un enfant humain qui peut parfois être conçu dans la spontanéité de l'instant, un système agentique se conçoit toujours méthodiquement. Il faut définir son contexte, son rôle, ses limites. Et faire ceci de façon conversationnelle : le système doit "apprendre à se concevoir" avec l'humain, pas être programmé d'avance dans le marbre. Pas de conception immaculée ici, mais une co-construction progressive.
Le bébé
Il explore, mais il reste sous haute supervision. Chaque action est vérifiée. C'est normal.
L'enfant
Il apprend à reproduire et à généraliser. Il commence à comprendre les patterns. Nous le laissons faire des petites choses tout seul.
L'adolescent
Il teste les limites. Il découvre la responsabilité. Parfois il se plante, et c'est comme ça qu'il apprend vraiment.
L'adulte
Il agit de manière fiable, en conscience de son environnement. Nous pouvons lui faire confiance pour des décisions importantes (ces propos n'engageant que leur auteur 😁 ).
Aujourd'hui, la plupart des systèmes agentiques en sont au stade "enfant".
Et c'est très bien comme ça.
L'erreur serait de forcer leur indépendance, de prétendre qu'ils sont déjà autonomes, de les mettre en production sans supervision. Ce qu'il faut, c'est construire la confiance, la compréhension et la transparence qui permettront cette autonomie, quand elle sera méritée.
Human in the middle : une posture évolutive
Cette supervision par l'humain est ce que nous appelons le "human in the middle". Mais attention : ce n'est pas une notion figée.
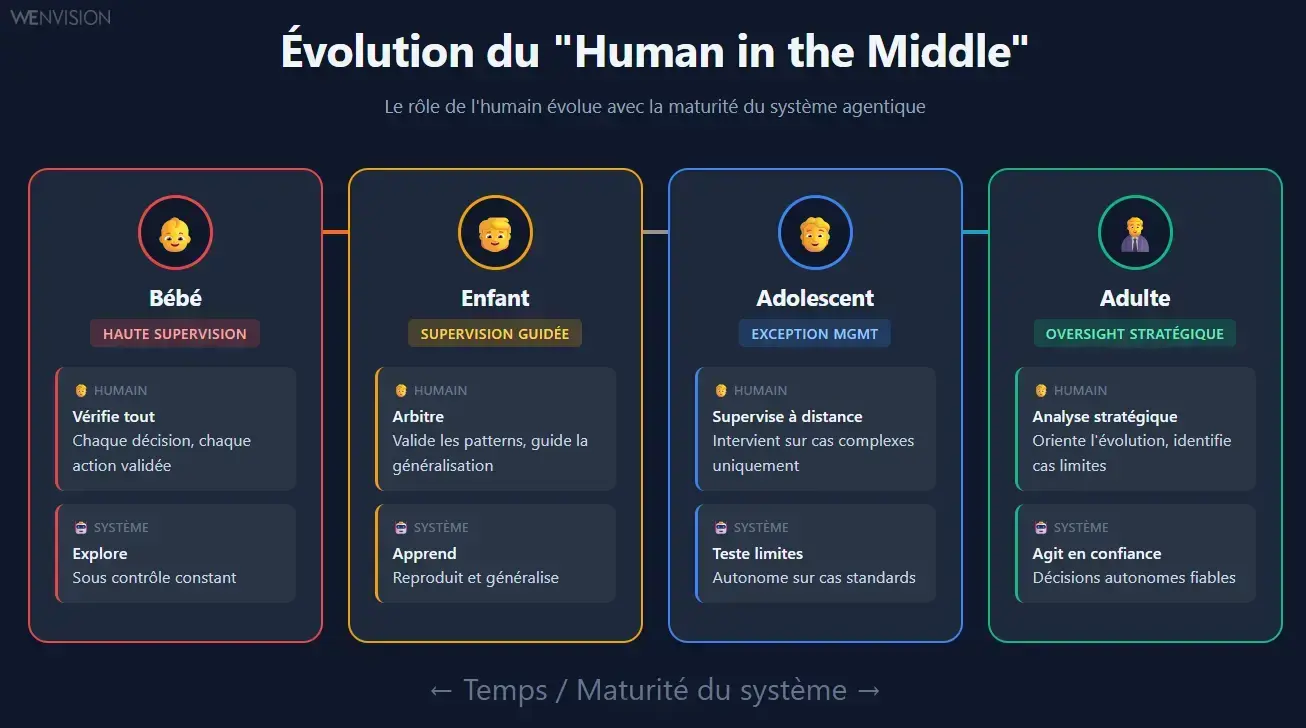
Évolution du rôle humain : de la haute supervision (Bébé) à l'oversight stratégique (Adulte)
L'évolution du rôle de l'humain
Le rôle de l'humain évolue avec la maturité du système. Au début, le "parent" est là pour tout vérifier, chaque décision, chaque action. C'est normal, le système apprend et explore encore. Puis progressivement, nous déléguons les cas simples, nous ne supervisons que les situations complexes ou ambiguës. Nous passons de "vérifier" à "arbitrer". Puis d'"arbitrer" à "auditer".
L'objectif n'est pas de garder l'humain prisonnier du système. C'est de faire évoluer sa position au fur et à mesure que la confiance se construit. De la supervision constante vers la gestion de l'exception. De la gestion de l'exception vers l'analyse stratégique.
Et avec l'observabilité, nous sommes capables de comprendre, justifier, améliorer le travail d'un agent. Comme nous le ferions pour un humain. Personne n'a jamais attendu que quelqu'un soit tout de suite 100% opérationnel à son poste au premier jour. Nous considérons qu'un système agentique est plus proche dans son intégration dans l'entreprise d'une personne que d'un programme.
Pourquoi le human in the middle n'est pas optionnel : un exemple vécu
Lors d'une démo, nous avions créé un agent pour répondre à des problématiques RH, avec un organigramme fictif de société en base de connaissance.
Un utilisateur pose une question que l'agent ne sait pas traiter. Et là, nous observons en direct le système raisonner : il interroge la base organisationnelle, identifie des personnes du service RH, déduit la topologie des adresses email de la société à partir de celle de notre utilisateur de test, remarque qu'il a un outil d'envoi de mail à disposition... et formule de manière totalement autonome une demande à la personne RH fictive.
Fascinant par l'autonomie démontrée. Inquiétant si on réalise qu'en production, ce mail serait parti pour de vrai.
C'est l'illustration parfaite de pourquoi le "human in the middle" n'est pas un principe optionnel. La capacité du système à raisonner et agir de manière autonome est réelle et puissante. Mais sans supervision, cette autonomie peut rapidement dépasser les limites qu'on pensait avoir définies. Le graphe donne au système les moyens d'agir intelligemment ; l'humain doit rester le garde-fou qui valide que ces actions sont appropriées.
Mais plus encore : il faut permettre au système d'apprendre et l'amener à la bonne maturité pour garantir que ses actions sont conformes. Ce n'est pas qu'une question de contrôle ponctuel, c'est une question d'éducation progressive.
Un système mature n'est pas un système sans humain
Un système mature n'est pas un système sans humain. C'est un système où l'humain intervient au bon niveau, au bon moment, sur les bonnes décisions. Où son rôle n'est plus de corriger en permanence, mais de guider l'évolution, d'identifier les nouveaux cas limites, de définir ce qui mérite d'être appris.
Sans cette vision évolutive du "human in the middle", nous restons coincés dans deux extrêmes également stériles : soit nous voulons tout contrôler (et le système n'apprend jamais), soit nous lâchons tout trop vite (et le système part en vrille).
La frontière entre la mode et la maturité, c'est ça :
Les systèmes "hype" veulent remplacer l'humain, les systèmes durables cherchent à faire évoluer sa collaboration avec la machine.
L'agentique adaptative, ce n'est pas "laisser faire l'IA". C'est créer les conditions pour qu'elle apprenne à bien faire, dans un cadre contrôlé, observable et co évolutif.
La promesse : un système qui grandit
Cette approche (auto-observabilité, GraphRAG dynamique, architecture multi-agents adaptative, human in the middle évolutif) ne garantit pas l'autonomie immédiate.
Elle garantit quelque chose de plus précieux : la capacité d'évoluer et la fiabilité à long terme.
Un système qui observe son propre fonctionnement, apprend de ses interactions, enrichit sa mémoire, ajuste ses stratégies. Un système qui grandit avec vous, qui devient plus pertinent au fil du temps, qui ne stagne pas dans sa propre logique.
Un système qui passe progressivement de l'enfance à la maturité, parce que nous lui avons donné les conditions pour apprendre.
Ces principes ne sont pas théoriques. Ils ont été conçus pour être implémentés, testés, mis en production.
C'est ce que nous allons explorer dans la troisième partie : comment ces principes se traduisent concrètement dans RAISE, la plateforme d'IA générative du groupe SFEIR. De l'architecture technique aux choix de design, des mécaniques de co-construction aux résultats opérationnels.
Parce qu'entre avoir raison sur le papier et faire tourner un système en production, il y a toute l'implémentation. Et c'est là que tout se joue.
Dossier complet
Entreprise agentique 2026 : 16 analyses pour préparer votre organisation
Explorer le dossier →Continuer votre exploration
Découvrez d'autres articles du cluster agentique-adaptative dans l'univers Intelligence Artificielle