L'IA offre un potentiel significatif pour rationaliser et optimiser la gestion du backlog Produit, mais son adoption nécessitera de trouver un équilibre judicieux entre automatisation et validation humaine, tout en assurant la transparence et en atténuant les risques de biais.
L'arrivée de l'intelligence artificielle (IA) bouscule les pratiques Agile. Que signifie encore "être Agile" à l'ère de l'IA? Cette série d'articles dresse un panorama des changements culturels et méthodologiques à prévoir au sein des organisations.
La maîtrise de la Data apporte la couche d'intelligence nécessaire pour analyser son marché, le fonctionnement de ses produits et prendre des décisions qui amélioreront le business. Maîtriser à la fois le management et la gouvernance de la donnée devient primordial ; c'est l'un des enjeux majeurs de 2023.
Les rôles de la data deviennent plus clairs
Des rôles pour la gouvernance et l’usage de la donnée
Le Chief Data Officer gouverne l’usage de la donnée
Le rôle du ou de la CDO est de construire une gouvernance de la donnée alignée avec la stratégie business de l’entreprise. Ce doit être un manager, quelqu’un qui a une vision sur la façon de mettre la donnée au service du business, qui embarquera les équipes, les acculturera, qu’il s’agisse des employés ou de ses pairs de la direction.
Le CDO doit être rattaché directement au Comex, afin de disposer des coudées franches pour transformer les usages et le partage de la donnée au sein de l’entreprise. Il doit pouvoir manager la donnée et son partage sans dépendre du bon vouloir du CIO.
Et même si ce n’est pas un rôle technique, le CDO devra disposer d’une connaissance globale de l’écosystème data et des technologies qui y sont associées.
Les Data Domain Owners gèrent leur domaine
Chaque grand domaine de l’entreprise est responsable de ses données. Cela devient même flagrant dès lors qu’on commence à raisonner en termes de Data Mesh. Les patrons des finances, du marketing, etc. sont donc de facto des Data Domain Owners, un rôle qu’ils délèguent à des personnes au sein de leurs équipes.
Ce sont des personnes qui ont une connaissance approfondie de la donnée métier, comprennent les enjeux du data-driven, ou comment et pourquoi il faut partager la donnée pour la valoriser. C’est à elles que reviendront des tâches cruciales, telles que décrire les jeux de données au sein des data catalogs, ou encore déterminer qui peut y accéder et sous quelles conditions (dans le cadre d’un framework de partage déterminé par le CDO).
Les Data Stewards assurent un fonctionnement fluide
Les Data Stewards jouent un rôle protéiforme, puisqu’ils aident les autres acteurs à définir les normes et processus de collecte, à s’assurer de la qualité des données, à résoudre certains problèmes… Ce sont eux aussi qui vont assister les utilisateurs de données pour s’assurer que ces dernières sont bien utilisées de manière appropriée, conformément aux règles de l’entreprise.
Des rôles pour la fabrication et l’exploitation des produits et plateformes Data
Les Data Architects établissent les principes directeurs
Les Data Architects dessinent les grandes lignes de la plateforme, ses principes directeurs et définissent l'articulation entre les composants. Ils possèdent des connaissances globales sur l’écosystème technique, sont conscients des spécificités techniques et donc des avantages et inconvénients des principaux produits, langages et types d’architecture et peuvent aider à coder si besoin.
Les Data Engineers mettent les idées à l’échelle
Les Data Engineers définissent, développent, mettent en place et maintiennent les outils et infrastructures permettant l’analyse de la donnée. Spécialisés dans les problématiques de croisement et de gestion des données à large échelle, ce sont eux qui vont implémenter les idées des Data Analysts.
Les Data Scientists peaufinent les modèles
Les Data Scientists construisent des modèles mathématiques de machine learning pour répondre à des problématiques métier. Dans la majorité des cas, ils s’appuieront sur des modèles existants qu’ils personnaliseront pour répondre à des enjeux opérationnels.
Mais surtout, le rôle des Data Scientists ne s’arrête plus à la mise au point des modèles ; désormais, ils travaillent conjointement avec les ML Engineers pour s’assurer que leur modèle produise des résultats cohérents et pertinents tout au long de leur cycle de vie.
Les ML engineers industrialisent les modèles
Les Machine Learning Engineers appliquent les principes du DataOps à la data science : industrialisation, fiabilité, observabilité, etc. Ils mettent en place toute l’infrastructure pour que les Data Scientists puissent tester et publier leur modèle de façon automatisée, mais aussi obtenir le feedback nécessaire pour mettre en œuvre de l’amélioration continue. Ce sont eux qui vont mettre les solutions IA à l’échelle et optimiser la performance globale des modèles. De plus en plus, l’aspect IA responsable devrait entrer dans leur champ de préoccupations.
Les Data Analysts - et à terme tous les utilisateurs
Les Data Analysts manipulent la donnée pour en tirer des enseignements clés, afin de résoudre des problèmes ou de prendre des décisions mieux informées. S’il s’agit aujourd’hui de rôles distincts, il est probable qu’on assiste dans le futur, avec l’acculturation de l’ensemble des collaborateurs à la donnée et la mise à disposition d’outils self-service “intelligents” (avec de l’IA pour des requêtes en langage naturel et des analyses poussées), à une disparition de ce terme. On évoquera alors plutôt des centaines de millions de personnes analysant de la donnée dans le cadre de leur travail quotidien, des graphistes, de propriétaires de pizzérias, de chefs de produits...
Les aspects organisationnels de la data en pole position
La dernière étude du cabinet spécialisé BARC sur le sujet de la data le montre bien : ce qui préoccupe le plus les entreprises aujourd’hui, ce sont les aspects de gouvernance, de management, d’organisation et d’architecture reflétant cette organisation. Comment s’organiser pour tirer au mieux parti de la donnée dans l’entreprise, c’est en effet la question cruciale, au-delà des choix technologiques.
Data mesh, pour un usage croissant et décentralisé
Lors de la construction d'un système d'information, le choix de l'architecture peut avoir un impact important sur l'efficacité et le rendement du système. Dans le domaine de l'architecture data, une architecture particulièrement bien adaptée aux systèmes basés sur les produits est le “data mesh”.
La notion de “mesh”, le maillage, favorise la création de produits répondant à des besoins spécifiques. Plutôt que de vouloir centraliser l’ensemble des données, l’approche data mesh laisse les responsables de domaines (Domain Data Owners) gérer leurs données, leur qualité, qui peut y accéder et sous quelles conditions… Les responsables produits vont créer des produits sur la base de ces données, et pourront être clients des données d'autres domaines. Chaque produit peut évoluer indépendamment en fonction des évolutions des besoins clients et de l’enrichissement de chaque domaine.
Ce découplage favorise aussi à son tour les architectures “event-driven”, les domaines informant le reste du SI d’événements se produisant en leur sein.
Cette approche fédérée plutôt que centralisée donne ainsi plus de latitude - qui ne doit pas être confondue avec de l’anarchie, où chacun ferait ce qu’il souhaite dans son coin. C’est pourquoi il est primordial d’instaurer des règles de gouvernance, de mettre en place les rôles et responsabilités nécessaires, mais aussi une plateforme et un outillage communs qui vont faciliter la création et la maintenance de ces produits data.
Data governance, le prochain terrain de jeu des hyperscalers
La gouvernance des données est un aspect essentiel de la valorisation des données. C’est toutefois un nom parfaitement impropre, qui amène à confondre data governance et data management. Le data management est une discipline étroitement liée à l’informatique, qui consiste à mettre en place l’outillage nécessaire pour gérer, sécuriser et partager les données. La gouvernance concerne les hommes et l’usage de la donnée : quels sont les rôles et responsabilités, quelles sont les règles d’accès à la donnée, les contraintes légales et éthiques respecter, pour quels usages…
Ces deux disciplines sont essentielles pour les organisations dans le paysage numérique actuel, car la prolifération des données et l'importance croissante de la prise de décision basée sur les données font que les organisations doivent disposer des bons outils et processus pour gérer et protéger leurs données tout en favorisant les initiatives data-driven.
L'un des principaux défis de la gouvernance des données est de trouver le bon équilibre entre l'accès et le contrôle des données. Si l'accès aux données n'est pas soigneusement géré, il existe un risque que des personnes non autorisées accèdent à des données sensibles, ce qui pourrait entraîner des failles de sécurité et des pertes de données. D'autre part, si l'accès est trop restreint, cela peut entraver la capacité des organisations à utiliser efficacement les données et à prendre des décisions basées sur les données.
Pour relever ce défi, les organisations doivent définir soigneusement les rôles et les responsabilités en matière d'accès aux données, établir des politiques et des procédures claires pour la gestion des données, et mettre en œuvre des technologies et des outils pour garantir la sécurité et l'intégrité de leurs données. En trouvant le bon équilibre entre l'accès et le contrôle des données, les organisations peuvent garantir la sécurité et la conformité de leurs données, et soutenir la prise de décision basée sur les données.
Ces dernières années, l'importance de la gouvernance des données a conduit au développement d'une gamme d'outils et de technologies pour soutenir des stratégies de gouvernance efficaces. Ces outils comprennent des catalogues et des dictionnaires de données, des outils de lignage et d'audit des données, ainsi que des outils de qualité et de sécurité des données. Ces logiciels peuvent aider les organisations à gérer et à protéger leurs données, et à assurer la conformité aux réglementations et normes pertinentes.
La croissance du cloud computing a également placé la gouvernance des données au premier plan des préoccupations de nombreuses organisations. Comme de plus en plus de données sont migrées vers le cloud, il est important pour les organisations de mettre en place des stratégies de gouvernance solides pour garantir un usage sécurisé de leurs données. D’autant que cela n’a souvent pas été fait avant, avec les datalakes de première génération. Le passage au Cloud est l’occasion d’inventorier les données et mettre des règles en place. Par conséquent, de nombreux fournisseurs de cloud computing proposent désormais des outils et des services pour soutenir la gouvernance des données, notamment des catalogues et des solutions de gestion et de sécurité des données.
Toutefois, l’enjeu principal reste l’acculturation des collaborateurs aux principes d’une bonne gouvernance et la mise en place d’une organisation adéquate.
La valorisation de la donnée ne sera possible que si les Data Domain Owners jouent le jeu du partage. Contrairement à l’or noir, le pétrole, la donnée ne s’épuise pas quand on la consomme, au contraire, elle crée de nouvelles données et enrichit à la fois son producteur et son consommateur.
Partager la donnée est la condition sine qua non d’une stratégie data-driven. Cela nécessite de la confiance, appuyée par le top management, mais aussi un cadre de gouvernance ainsi que des outils appropriés pour exposer les jeux de données, expliciter leur nature et leur niveau de qualité, indiquer les conditions d’accès, plus des outils capables d’authentifier les droits des utilisateurs et de leur donner accès ou non aux données.
Moins de Datalabs et autres Data Factories, plus de DataOps et MLOps
La donnée en tant que terrain de jeu et d’expérimentation touche à sa fin. La crise économique aidant, il s’agit aujourd’hui d’industrialiser les projets, de les déployer à l’échelle et de démontrer la capacité à soutenir des processus business et créer de la valeur.
C’est tout l’enjeu des approches DataOps et MLOps, pour la data et le machine learning : fournir un ensemble de bonnes pratiques pour mettre la donnée et l’IA au service de l’entreprise, de la même façon que le concept DevOps entend fluidifier, accélérer et sécuriser la production et le déploiement des logiciels.
DataOps et MLOps fournissent le guide d’utilisation pour mettre en place du CI/CD, de l’automatisation et de l'observabilité, toutes conditions nécessaires à une approche industrielle.
La Data Observability devient un enjeu industriel
L’industrialisation de la sphère data conduit à mesurer - et optimiser - le coût de ce qu’on produit mais aussi sa qualité. Comme les devops et le SRE, l’ingénieur data a besoin de se poser les bonnes questions lorsqu'il s'agit de mettre en production les pipelines de données. Il faut penser logs, métriques ou encore traces pour répondre aux questions : "Est-ce que ma donnée est à jour ?" , "Est-ce que les schémas ont changé ?" ou "Est-ce que mon pipeline alerte les équipes lorsqu'il y a des erreurs."
FinOps arrive dans la data
Le fait de penser la data en termes de produits amène à en considérer les clients, les ingrédients, les moyens de fabrication, le cycle de vie… ainsi que les coûts associés. Les produits Data doivent créer de la valeur au regard des investissements consentis. C’est un impératif opérationnel et économique.
Les ingénieurs data qui passaient beaucoup de temps sur les enjeux de fiabilité et de performance devront aussi prendre en considération l’optimisation des coûts.
Les projets data ne doivent plus démarrer sans une composante FinOps, de façon à pouvoir attribuer les coûts aux différents domaines métiers, et à mesurer ces investissements à l’aune de la valeur business créée. La démarche FinOps s’assurera aussi que les bonnes pratiques sont respectées tout au long du projet, par exemple la mise en place de seuils et de quotas qui déclencheront des alertes, voire stopperont un service.
La technologie data se stabilise
Il reste des innovations dans le domaine de la data, mais 2023 devrait davantage être une année de consolidation et d’industrialisation des concepts que nous manipulons depuis quelques années.
SQL, langage universel
SQL est un langage puissant et polyvalent utilisé pour gérer et manipuler les données stockées dans des bases de données. SQL a pour lui sa simplicité et sa facilité d'utilisation. Il utilise une syntaxe familière et intuitive qui permet aux utilisateurs d'écrire rapidement et facilement des requêtes pour extraire, modifier et manipuler les données dans la base de données. Cela en fait un langage idéal pour les personnes qui doivent accéder aux données de leur organisation et les analyser.
Avec la prolifération des plateformes de données et la quantité croissante de données générées, l'utilisation de SQL devient plus importante que jamais. SQL fournit un langage commun qui peut être utilisé pour accéder aux données et les analyser à partir de diverses sources, notamment les feuilles de calcul, les fichiers plats, les bases de données NoSQL et les entrepôts de données traditionnels. Cela permet aux organisations de tirer rapidement et facilement des enseignements de leurs données et d'objectiver leurs décisions.
Tous les systèmes qui stockent ou exposent de la donnée offrent désormais une prise en charge de SQL, ce qui permet aux utilisateurs d'écrire des requêtes qui combinent des données provenant de plusieurs sources et d'effectuer des analyses avancées. Les avancées récentes vont jusqu'à l'intégration de modèles IA et de ML directement dans le langage.
Depuis plusieurs années, SQL poursuit son retour en grâce. Ce sera sans aucun doute un des langages les plus utilisés par les Citizen Developers.
L’ELT détrône l’ETL
L’extraction des données sources et leur chargement dans les systèmes cibles a longtemps été l’apanage des ETL (Extract, Transform & Load). A l’époque où il s’agissait de capter les données d’un système transactionnel pour les injecter au bon format au sein des entrepôts de données (datawarehouses), les outils ETL réalisaient toutes les opérations de transformation nécessaires entre les deux.
L’avènement des nouvelles architectures de données privilégie le plus souvent le chargement des données brutes au sein d’un datalake. L’étape de transformation est réalisée ensuite, si elle s’avère nécessaire, pour injecter les données au sein du datawarehouse. De cette façon, les data scientists auront accès aux données brutes et, si de nouveaux besoins analytiques émergent, de nouvelles transformations pourront être opérées à partir des données brutes.
Ce changement vers l’ELT (extraction, chargement, puis transformation) a aussi été rendu possible par les nouvelles capacités offertes par les plateformes analytiques Cloud, où l’usage du processeur et de la mémoire n’est plus aussi contraint que dans les datawarehouses traditionnels.
Cela bouleverse forcément le marché des outils d’ingestion de données, qui a vu aussi naître des outils qui se consacrent spécifiquement à la transformation. Le premier d’entre eux est le framework dbt, qui jouit d’une énorme popularité - notamment parce qu’il permet de décrire les transformations de données de façon modulaire, de les tester et de les documenter - la documentation produite intégrant automatiquement le lignage de la donnée. Du point de vue du développeur, cependant, la qualité du code peut laisser à désirer, ce qui conduit des entreprises à s’intéresser à un framework plus récent, Dataform (racheté puis intégré à Google Cloud Platform), qui doit encore améliorer ses fonctionnalités.
Ce découpage entre EL & T et l’évolution vers la Data-as-code nous paraissent en tout cas actés.
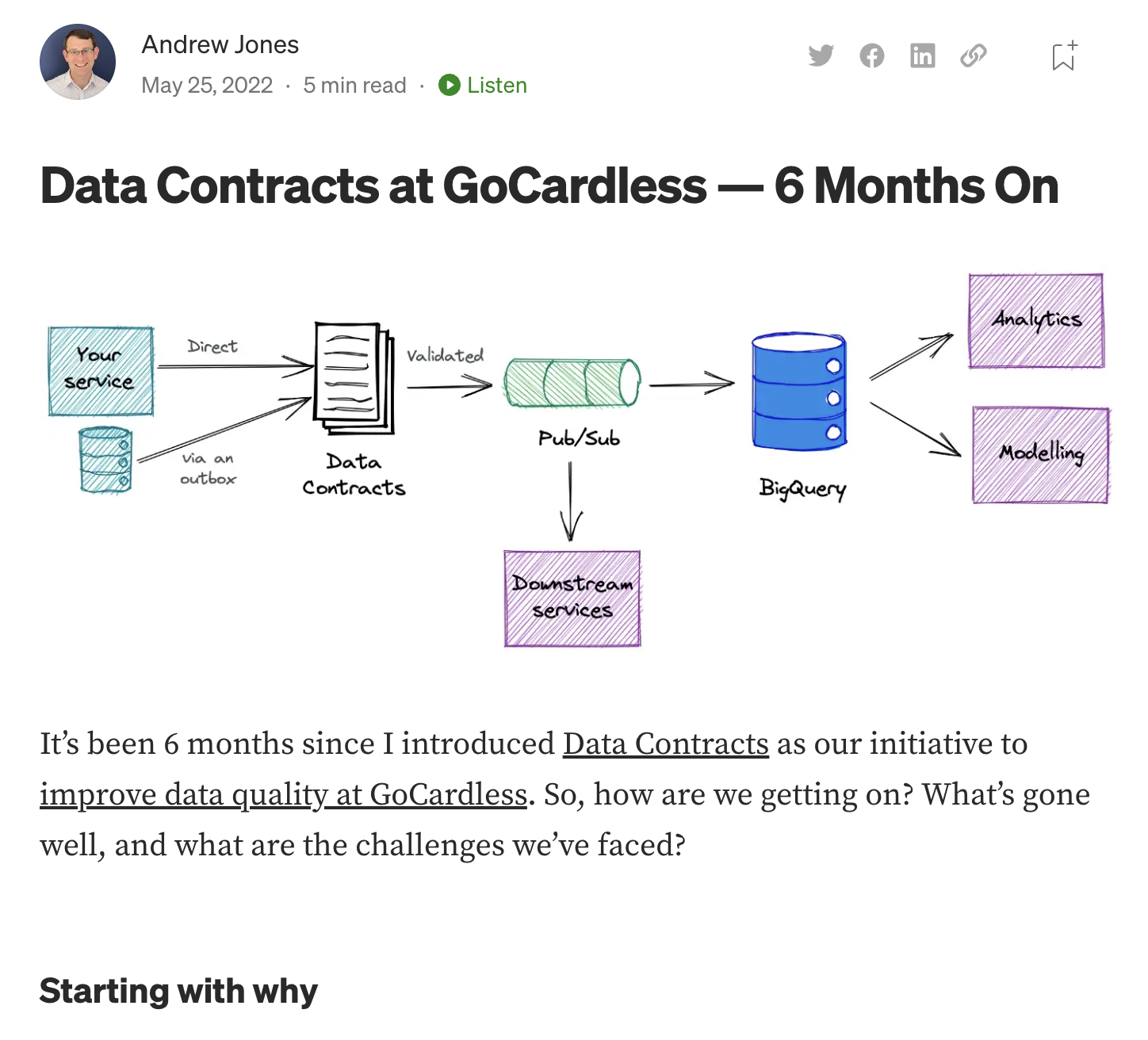
Les Data Contracts assurent la confiance et la conformité dans une architecture distribuée
Les Data Contracts (contrats de données) sont des accords entre les producteurs de données et les consommateurs de données qui décrivent les attentes et les exigences en matière de qualité et de cohérence des données.
Ce concept est très largement associé au data mesh et aux architectures distribuées, lorsque des domaines utilisent des data products d’autres domaines. Les contrats sont conçus pour résoudre le problème des changements de schéma inattendus, qui peuvent causer des problèmes de qualité des données et perturber les systèmes aval.
La notion de Data Contract est récente mais commence à prendre, avec l’essor du data mesh. En 2023, les contrats de données sont susceptibles de devenir une bonne pratique plus largement adoptée.
Les bases orientées documents alliées du “move to cloud”
Les bases de données orientées document, comme MongoDB, sont des bases de données NoSQL populaires et open source qui sont utilisées pour stocker et gérer des données dans un format flexible et orienté vers les documents. Ces bases n'utilisent pas de schéma fixe pour organiser les données. Au lieu de cela, elles stockent les données dans des documents, qui sont des collections pouvant avoir différentes structures et être facilement modifiées.
Elles sont conçues pour être évolutives et flexibles, ce qui en fait un bon choix pour les entreprises qui doivent s'adapter rapidement à l'évolution de leurs besoins. Ce modèle peut être utilisé pour stocker et gérer un large éventail de types de données, notamment des données structurées, semi-structurées et non structurées.
L'un des principaux avantages de ces bases est leur performance. Elles sont capables de traiter de grands volumes de données et des niveaux élevés de débit, ce qui le rend adaptées aux applications ayant des exigences élevées en matière de performances. Elles sont également hautement disponibles et peuvent être facilement déployées sur une infrastructure basée sur le cloud. C'est pourquoi leur succès lors de programmes move to cloud est grandissant.
En revanche, ces bases ne sont pas adaptées à tous les cas d’usage, et développer des applications mettant à profit les capacités NoSQL demande un état d’esprit et des compétences spécifiques par rapport aux développements traditionnels.
“No Backend” et services managés, pour se concentrer sur l’essentiel
Qu’on parle de “no backend”, de service managé ou de “serverless edge functions”, le principe prend de l’ampleur dans le monde des bases de données : il s’agit de se concentrer sur le fonctionnel, et de laisser le management de la base à un service cloud, qui réalisera la maintenance, la sauvegarde, les montées de version, etc.
Le moteur PostgreSQL est ainsi proposé par de multiples services, chez les fournisseurs de cloud, mais aussi dans l’open source, avec Supabase, une solution créée comme une alternative à Firebase et qui monte dans l’écosystème.
Data Lakehouse, l’autre nom d’une Data Platform
Le concept de Data Lakehouse, poussé par des acteurs comme Databricks, Starburst ou Cloudera, vise à apporter “le meilleur des deux mondes”, le datalake et le datawarehouse.
Pendant longtemps, les datawarehouses étaient les seuls outils à notre disposition pour stocker et préparer les données structurées aux fins d’analyse de type BI. Les datalakes ont permis d’accueillir beaucoup plus de données, notamment des données non structurées (images, texte, vidéos…). Ils sont aujourd’hui régulièrement utilisés de manière conjointe, au sein d’une Data Platform dans le cloud, le datalake ingérant la donnée brute, dont une partie sera transformée et injectée dans le datawarehouse.
L’idée des Data Lakehouse est de s’appuyer sur un unique produit apportant l’ensemble des fonctionnalités ; toutefois, les opérations de transformation, par exemple, devront toujours exister. Data Lakehouse unique ou Data Platform utilisant conjointement deux produits ou plus, le principe est très proche et devient la pierre angulaire des infrastructures data modernes.
La capacité à créer des produits avec de la data raffinée commence à sortir du cadre analytique pour revenir dans le cadre opérationnel. Un cas d’usage de plus en plus fréquent concerne les référentiels clients uniques, constitués au sein d’une data platform à partir de plusieurs bases clients de différents systèmes opérationnels (CRM, ventes, abonnements, SAV, etc.). Les données réconciliées, nettoyées, dédoublonnées, peuvent être réinjectées pour venir servir des systèmes opérationnels, sous forme de produits data mis à disposition au sein d’un hub de données, ou injectées directement dans une application (opération de type reverse-ETL).