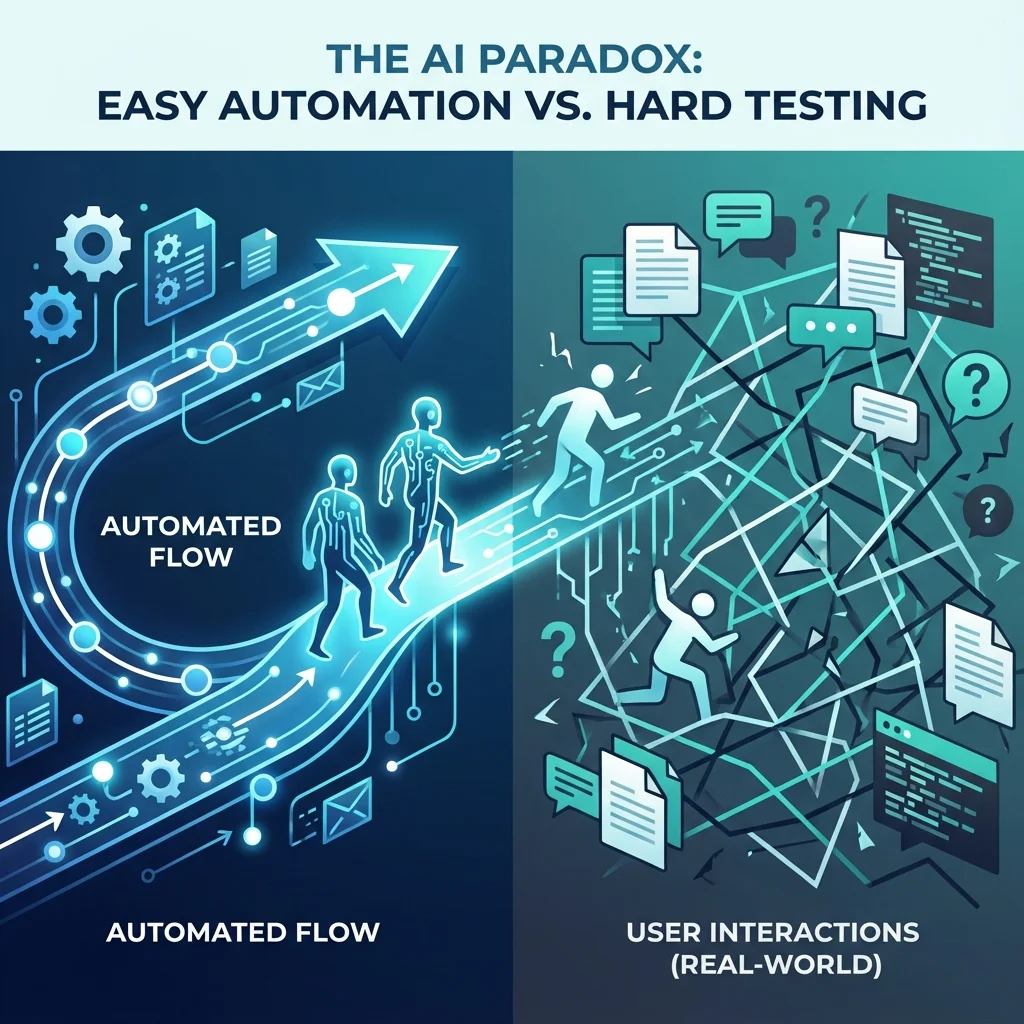
Le paradoxe des agents IA : tout le monde veut automatiser, mais personne n’est prêt à tester vraiment
Nous vivons un paradoxe fascinant.
Les entreprises rêvent d’agents autonomes, de copilotes intelligents, d’orchestrateurs capables de transformer les process en flux continus. Elles investissent, prototypent, lancent des POC brillants… puis tout s’arrête au même endroit : la mise en production.
Sur le papier, les agents doivent fluidifier les opérations. Dans la réalité, ils deviennent une source de friction inattendue. Chaque ajustement semble anodin — modifier un prompt, ajouter un outil, changer une policy — mais déclenche une réaction en chaîne. Il faut tout retester. Encore. Et encore.
Le résultat est toujours le même : 90 % du temps est absorbé par l’évaluation, et non par l’amélioration.
Ce n’est pas un échec des équipes. C’est un échec du paradigme actuel : nous essayons de faire entrer un comportement non-déterministe dans les méthodes de QA du logiciel classique. Et ça ne fonctionne pas.
Nous avons créé un nouvel actif numérique — l’agent — sans créer les outils pour le juger correctement.
C’est cela, aujourd’hui, le vrai blocage au scale.
Le coût invisible d’un agent mal évalué
Lorsqu’un agent semble “bien fonctionner” dans un environnement contrôlé, la tentation est grande d’avancer. Mais la performance en laboratoire est une illusion confortante. Les utilisateurs, eux, apportent le chaos du réel :
- requêtes mal formulées,
- documents incomplets,
- contextes ambigus,
- scénarios jamais envisagés dans les tests internes.
Un agent qui paraît fiable en interne peut s’effondrer dès le premier contact avec un utilisateur lambda. Et cet écart entre tests idéalisés et usage réel a un coût massif : dérive de qualité, perte de confiance, frictions opérationnelles, voire risques légaux dans certains métiers sensibles.
Nous avons trop longtemps accepté cette situation comme une fatalité.
Il est temps de la remettre en question.
La clé : passer d’un jugement partiel à une évaluation holistique
Chez WEnvision, nous sommes arrivés à une conviction simple : pour juger un agent autonome, il faut juger sa trajectoire, pas seulement sa réponse.
Et cela nécessite 5 juges complémentaires — cinq niveaux d’évaluation qui couvrent enfin la complexité du comportement agentique.
1. Les Metrics automatisées
Elles jouent le rôle de premier filtre : rapides, reproductibles, précieuses pour les régressions flagrantes. Mais elles restent aveugles à la logique. Elles ne capturent ni la cohérence, ni la solidité du raisonnement.
2. LLM-as-a-Judge
Le juge qui scale.
En comparant A vs B, il détecte les nuances qu’aucune métrique classique ne peut voir. C’est le meilleur signal automatisé pour évaluer la qualité réelle d’un output.
3. Agent-as-a-Judge
Le critique interne.
Il ne regarde pas la réponse finale, mais tout le processus : plan, choix d’outils, robustesse technique. Il détecte les plans absurdes, les étapes inutiles, les appels d’API erronés — même lorsque la réponse semble correcte.
4. L’humain dans la boucle (HITL)
Le garant de la vérité métier.
Il fixe le “Golden Set”, tranche les cas ambigus, apporte la nuance culturelle, sectorielle, éthique que l’automatisation ne peut pas reproduire.
5. Le feedback utilisateur
Le juge final.
Chaque interaction en production devient un signal précieux, attaché à la trace complète du raisonnement. C’est lui qui révèle les dérives, les incompréhensions et les vrais irritants.
Tester, ce n’est pas valider : c’est comprendre le réel
L’erreur la plus répandue aujourd’hui est de croire que des tests internes positifs suffisent à déployer un agent en production.
La vérité, c’est que “ça marche” n’a aucun sens tant que cela n’a pas été confronté au réel. Les agents sont exposés au bruit, à la diversité des intentions, aux inconsistances du monde humain.
Ils ne doivent donc pas être évalués comme des programmes, mais comme des systèmes socio-techniques. Des systèmes qui apprennent, qui interprètent, qui adaptent — et qui peuvent dériver.
La seule manière de garantir leur fiabilité est de les évaluer à plusieurs niveaux, en continu, et au plus proche de l’usage final.
L’avenir du scale des agents ne dépend pas des modèles, mais des juges
Les entreprises qui réussiront ne seront pas celles qui ont les agents les plus sophistiqués.
Ce seront celles qui auront construit un système d’évaluation fiable, nuancé et continu.
Un système capable de détecter les régressions, d’interpréter les trajectoires, de contextualiser les réponses et d’intégrer la réalité humaine et métier.
Sans ce cadre, tout déploiement d’agent n’est qu’un POC un peu mieux habillé.
L’enjeu n’est pas technique.
Il est méthodologique, organisationnel, stratégique.
L’avenir n’est pas un agent plus intelligent.
L’avenir est un agent mieux jugé.
Êtes-vous prêt à mettre vos agents face au réel — et à supprimer enfin le vrai goulot d’étranglement de leur adoption ?
Continuer votre exploration
Découvrez d'autres articles du cluster agents-systemes-agentiques dans l'univers Intelligence Artificielle