
Au-delà du code : un repo, un agent et un IDE pour tout livrer
Nous sommes entrés dans l'ère des meta-agents. Pas les agents IA eux-mêmes, ceux-là, nous les utilisons depuis un bon moment. Non, ce qui émerge aujourd'hui c'est la couche au-dessus : des frameworks qui orchestrent le travail des agents, gèrent leur état, structurent leur collaboration. Et ça change tout. Pas seulement pour le code.
Dans cet article, je partage mon expérience avec ces outils, et notamment un workflow qui combine Claude Code (Opus) et Codex (GPT-5.4) en pair programming IA. Mais surtout, j'explique pourquoi cette approche dépasse largement le développement logiciel : architectures, audits, veille techno, réponses à appels d'offres.
Le form factor repo + meta-agent + agent + IDE est en train de devenir le couteau suisse universel du delivery.
Et ça change profondément ce qu'un consultant peut livrer. Et derrière les outils, une conviction : le consultant de demain ne livre plus un document figé, il livre un système vivant qui continue de produire de la valeur après la mission.
Ce qui a vraiment changé
Il y a un an nous faisions déjà du "vrai" code avec des agents IA. Claude Code existait, GitHub Copilot aussi, Cursor montait en puissance. Nous écrivions du code dans l'IDE, l'IA complétait, corrigeait, refactorait. C'était déjà puissant.
Ce qui a changé depuis, c'est trois choses.
D'abord le tooling des agents eux-mêmes. Les agents sont devenus plus fiables, plus capables, plus autonomes.
Les MCP (Model Context Protocol) ont standardisé l'interface entre les agents et les outils externes : une sorte de Swagger AI-ready qui a démocratisé l'accès à des centaines de solutions sur étagère, bases de données, API, services cloud, sans avoir à faire de la tuyauterie.
Les skills ont ajouté une couche supplémentaire : un mix d'instructions et d'outils qui permet de jalonner le comportement des agents avec des règles d'architecture, de sécurité, de coding practices. Les hooks permettent de déclencher des actions automatiques à chaque étape du cycle. Et nous ne citons pas tout, l'écosystème foisonne.
La fiabilité a fait un bond.
Ensuite, et c'est peut-être le plus important : les process d'ingénierie logicielle sont en pleine mutation. L'architecture, la gestion de projet, les pratiques de dev, tout s'adapte à la réalité des agents IA. Nous ne codons plus pareil quand un agent peut exécuter 25 plans en autonomie sur un projet. Les specs changent, le découpage change, la validation change. La position du dev elle-même change. C'est une vraie mutation.
Et enfin, ce que j'appelle les meta-agents. Ce sont des frameworks qui ne sont pas des agents eux-mêmes, mais qui structurent et orchestrent le travail des agents : découpage en phases, gestion de l'état, planification, vérification. C'est là que ça devient passionnant.
Les frameworks qui structurent le delivery
BMAD (Breakthrough Method for Agile AI-Driven Development), l'approche la plus complète côté spec-driven development. 12+ agents spécialisés (Analyst, PM, Architect, Scrum Master, Dev...), des workflows structurés phase par phase, et depuis la V6 le support natif des Agent Teams de Claude Code. C'est excellent pour du dev en équipe, et le moteur de brainstorming est vraiment bon. Par contre c'est pas vraiment adapté au dev solo ou en petite équipe. La mécanique complète (sprint ceremonies, story points, stakeholder syncs...) peut générer du bruit de spécification qui ralentit plus qu'il n'aide quand nous sommes tout seul devant notre terminal.
Les catalogues awesome-claude-code, l'écosystème a explosé. Skills, hooks, slash-commands, orchestrateurs, applications, plugins... des milliers de ressources référencées et curées par la communauté. C'est la porte d'entrée pour découvrir ce qui existe et constituer sa boîte à outils.
GSD (Get Shit Done), un framework créé par glittercowboy (TÂCHES), un dev solo qui voulait un système efficace sans le overhead des méthodologies enterprise. 44k+ stars sur GitHub. Attention, le nom est trompeur : c'est pas du vibecoding. C'est une approche très concrète et méthodique du travail de l'IA qui répond justement aux enjeux que nous avons quand nous produisons en solo ou en petite équipe. Nous avons besoin de structurer et d'uniformiser nos approches, sans sacrifier aux specs, à la planification, à la vérification, mais sans le bruit non plus. C'est celui que j'utilise au quotidien.
Ces approches ont chacune leurs forces. BMAD est solide pour du dev en équipe avec un vrai moteur de brainstorm et une approche spec-driven. Les catalogues de skills sont indispensables pour constituer sa boîte à outils. GSD colle bien au dev solo et en petite équipe. C'est celui-ci que je vais utiliser pour illustrer la suite, mais les principes s'appliquent à n'importe quel framework structuré.
Le point commun de tous ces meta-agents : ils viennent au-dessus des process de code assisté par IA courants (skills, hooks, etc.). Nous parlons vraiment de process agentique : comment orchestrer le travail d'un agent sur la durée, phase par phase, avec de l'état, de la validation, de la traçabilité. Compatibles avec Claude Code, Codex, Gemini CLI, Antigravity, et le partage d'état étant global (des fichiers markdown dans un repo), nous pouvons mixer les providers à notre guise.
GSD en pratique : les fondamentaux
Pour comprendre ce qui suit, il faut poser les bases de comment GSD fonctionne. Je ne couvre ici que le cœur du système. GSD a plein d'autres mécaniques (milestones, quick phases, workstreams, mode autonome, node repair automatique, agent researcher intégré, forensics, dashboard de stats projet...) mais vous aurez l'idée.
Le cycle d'une phase
Le point de départ : nous découpons le projet en phases. Chaque phase est un bloc de travail cohérent, avec un objectif clair. Nous discutons brièvement de ce découpage avec l'agent, puis chaque phase passe par quatre étapes :
Discuss : nous discutons le scope de cette phase avec l'agent. Pas une spec de 40 pages, un contrat de frontière : voilà ce que la phase contient, voilà ce qu'elle ne contient pas, voilà ce que l'agent peut décider seul, voilà ce que nous reportons à plus tard. Ça produit un CONTEXT.md.
Plan : l'agent produit un plan d'exécution avec des critères de succès machine-vérifiables. Pas du flou genre "implémenter le module d'auth", des truths vérifiables : "le endpoint POST /auth/login retourne un JWT signé avec RS256", "le refresh token expire après 7 jours", etc. Un plan-checker automatique valide la cohérence avant que nous touchions une ligne de code.
Execute : l'agent suit le plan tâche par tâche, commits atomiques. Quand la réalité diverge du plan (et ça arrive toujours), les déviations sont documentées, pas cachées. "Port 8080 → 8081, conflit avec service existant". Accepté, tracé, nous avançons.
Verify : le verifier relit le CONTEXT original et vérifie chaque truth. Score : 4/4, 3/4, avec l'evidence pour chaque point. Ce qui ne peut pas être vérifié automatiquement est marqué human_needed avec des critères clairs.
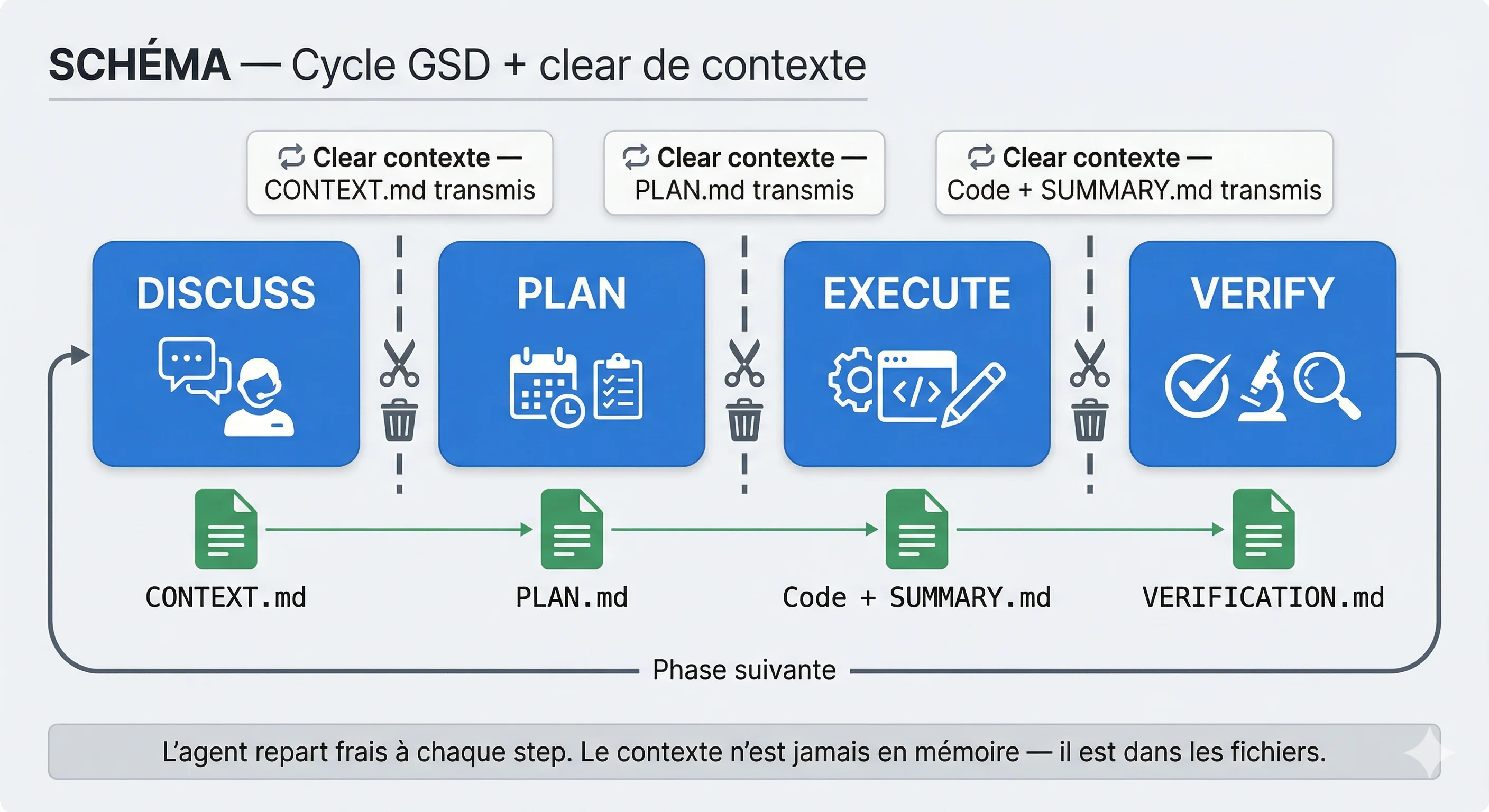
Ce qui résout le problème du contexte
Quand nous bossons avec un agent IA, tout va bien pendant 10 minutes. Le contexte est frais, l'agent est sharp. Et puis au bout de 15 minutes, la fenêtre de contexte se remplit, la qualité baisse, nous commençons à tourner en rond. Solution classique : nous compactons la conversation, nous maintenons un CLAUDE.md à jour, nous gardons des docs de contexte... mais c'est jamais vraiment suffisant. Nous sommes toujours en train de gérer le contexte au lieu de bosser.
La feature killer de GSD : le contexte est clearé entre chaque step. Entre le discuss et le plan, entre le plan et l'execute, entre l'execute et le verify, nous repartons d'un contexte vierge à chaque fois. Aucun besoin de garder du contexte en mémoire puisqu'il est écrit dans les fichiers de la phase. Et il est écrit d'une façon assez smart pour que l'agent retrouve immédiatement ses petits. Nous disons "reprenons" et Claude check le status, identifie la phase en cours, lit les artefacts, et sait exactement où il en est.
Ça donne aussi du parallélisme naturel : comme l'état est dans des fichiers et pas dans une conversation, nous pouvons lancer deux Claude Code en parallèle sur des phases différentes. Et au sein d'une même phase, les tâches indépendantes peuvent tourner en parallèle aussi.
Et c'est adaptable. J'en ai fait ma propre version avec notamment une gestion de la phase de "fix" après développement, des skills et hooks dédiés pour jalonner la vision architecture, sécu, coding practices. Le système s'adapte à vous, pas l'inverse. Et les skills ? Nous pouvons les faire générer par l'IA elle-même.
La validation croisée multi-provider : du pair programming IA
C'est là que ça devient vraiment intéressant. Et c'est, je pense, un des patterns les plus sous-estimés aujourd'hui.
Le principe
Claude Code avec Opus et Codex avec GPT-5.4, ce sont deux agents qui, bien pilotés, sont de vrais couteaux suisse du dev, chacun avec de sérieux atouts. Les deux sont capables de planifier, coder, reviewer, debugger. Nous pourrions utiliser l'un ou l'autre sur l'ensemble du cycle.
Mais j'ai trouvé qu'ils sont meilleurs ensemble que chacun de leur côté. Mon workflow : Opus fait la réal (discussion des phases, planification, exécution) et GPT-5.4 intervient à chaque étape du cycle GSD, après la discussion d'une phase, après la planification, après l'exécution. Il challenge chaque résultat d'Opus, systématiquement.
Et comme je me retrouvais à faire des allers-retours entre les deux agents, j'ai fini par construire un petit mécanisme qui leur permet, au sein de VSCode, de directement se parler entre eux. Je présenterai ça un autre jour parce que c'est assez marrant, mais le résultat c'est que mes plans sont plus quali, mes exécutions aussi, et le gain de fiabilité est assez gigantesque. Ça élimine énormément d'allers-retours.
C'est du pair programming, mais entre IA de providers différents. Et c'est là que ça devient puissant.
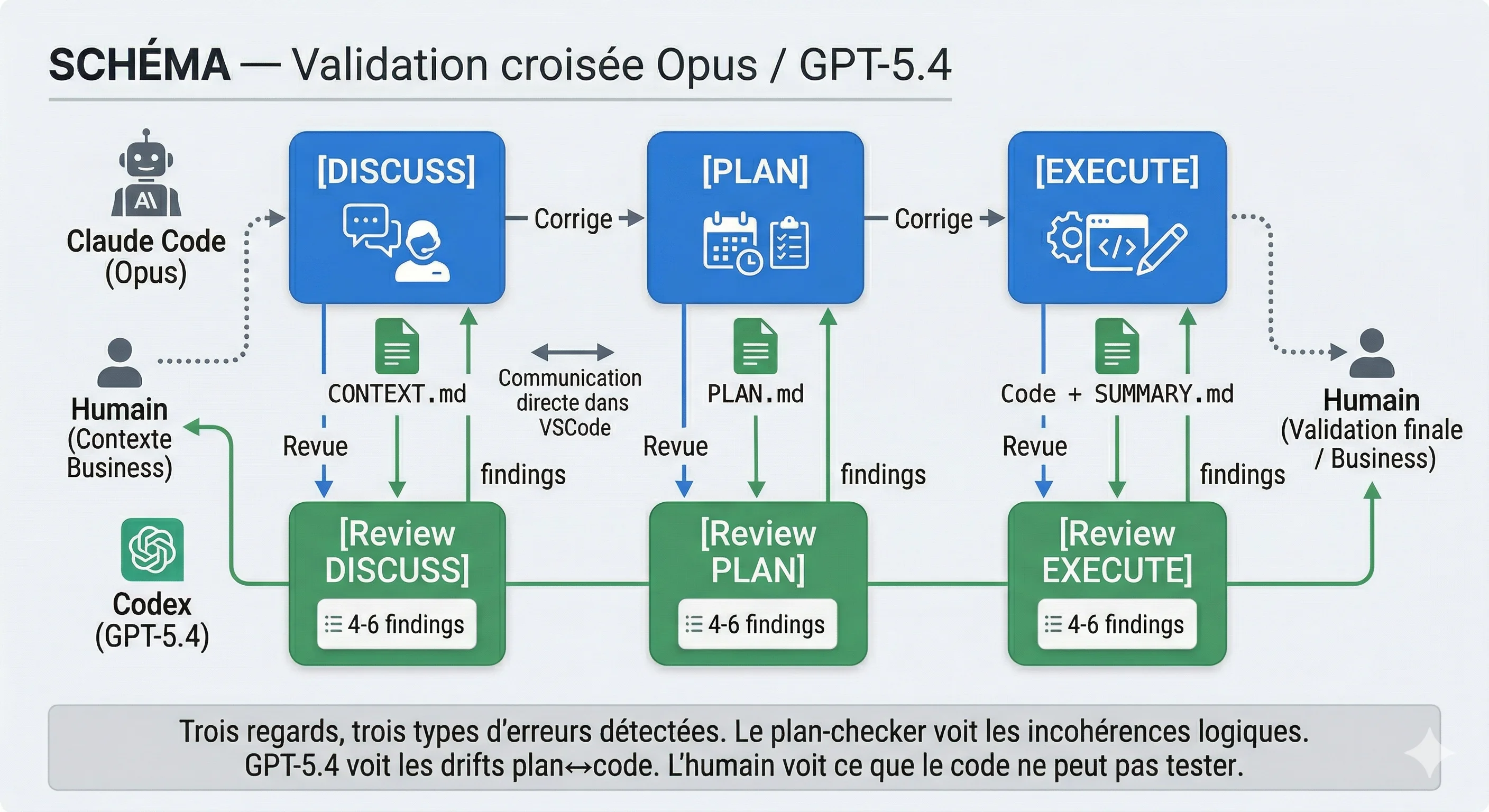
Pourquoi ça marche
Un seul agent, même excellent, ne challenge pas ses propres hypothèses. Si Claude Code planifie et exécute, il peut référencer une API qu'il pense exister, oublier une assertion devenue obsolète, dériver du scope sans le réaliser. C'est normal, il a construit le raisonnement, il est dans sa propre logique.
GPT-5.4 arrive avec un contexte frais et des biais différents. Un autre modèle, une autre approche du raisonnement, un œil neuf. Il lit le plan, il lit le code, et il trouve des trucs. Systématiquement. Et Opus corrige immédiatement, les findings sont quasi systématiquement pertinents.
C'est le même principe que le pair programming humain : le second regard attrape ce que le premier ne voit pas. Sauf qu'ici les deux "développeurs" ont des architectures cognitives fondamentalement différentes, ce qui maximise la diversité des erreurs détectées.
Un exemple concret
Sur une phase d'observabilité agent (un projet de composition musicale IA), GPT-5.4 a trouvé 4 problèmes dans le plan avant toute exécution de code :
getArrangement()était référencé dans le plan, cette API n'existait pas sur le SectionStore- Le plan supprimait un composant du DOM mais oubliait le container parent
- Un event listener était câblé en double
- Un état
skippedétait défini dans les types mais jamais émis par aucun composant
Chacun de ces bugs aurait coûté du temps de debug en exécution. Attrapés en lecture statique, avant d'avoir touché une ligne de code. C'est pas de la magie, c'est juste un regard différent, avec un modèle différent, sur les mêmes artefacts.
Les findings deviennent des commits dédiés :
844e4f0 fix(09.1): address 4 plan issues from code review
b321d92 docs(09.1): fix context inconsistencies from code review
En moyenne je vois 2-3 findings par phase. Rarement des problèmes critiques, mais suffisamment pour fiabiliser tout le process, apporter des perspectives nouvelles, et surtout s'assurer que le plan ne dérive pas de l'ambition initiale.
Trois niveaux de validation
Au final le système a trois angles de validation, chacun voyant des classes d'erreurs différentes :
Le plan-checker GSD voit les incohérences logiques internes au plan. GPT-5.4 voit les drifts entre l'intention et l'implémentation, API inexistantes, assertions obsolètes, scope drift. Et l'humain voit ce que le code ne peut pas tester : est-ce que l'UX est naturelle ? est-ce que la décision d'architecture tient la route dans le contexte business ?
Couplé aux skills et hooks dédiés, le système est quasi indépendant et produit des solutions solides. Nous sommes très loin du vibecoding, mais les résultats sont absolument bluffants.
Au-delà du code : le form factor universel
Et maintenant le point que je trouve le plus important.
Tout est un repo

Ce workflow, je ne le réserve pas au code. Pas du tout.
Je dois produire un document d'architecture nécessitant de multiples interviews, collecte de données, recherches profondes sur le web ? C'est un projet dans mon IDE.
Une réponse à un appel d'offres avec 3 lots à évaluer, des questions de clarification, des matrices de scoring ? Projet IDE.
Un audit de maturité IA pour un client ? De la veille techno sur les frameworks agentiques ? Une présentation de suivi de projet ? Du Terraform ? Un problème bureautique ?
Le form factor le plus efficace pour traiter tous ces besoins, c'est le repo, le meta-agent (ou le gestionnaire de process agentique, appelez-le comme vous voulez), l'agent, et l'IDE. Pas besoin de plus.
Ah si, l'expertise et la vision. Parce que toutes les décisions, tous les choix sont faits par l'humain. Nous réduisons juste la part qui n'est pas le fruit de notre créativité.
Un exemple : architecture d'une plateforme agentique
Un projet d'architecture pour un grand distributeur français. Le livrable : un document d'architecture complet, des ADR avec matrices de décision pondérées, des déclinaisons par use case.
Voilà comment ça se passe concrètement.
J'ai un dossier docs/ dans lequel je range tous les éléments bruts : transcripts de réunions, documents fournis par le client, comptes-rendus d'interviews, référentiels d'architecture existants. Tous les inputs, tels quels.
J'ai mon plan GSD avec mes objectifs par phase, et je vais processer via Claude Code ces documents en knowledge intermédiaire, des fichiers computés par l'IA sur la base des documents bruts. Des synthèses d'interviews, des analyses comparatives, des benchmarks techniques, des mappings de contraintes. Je simplifie, parce que bien sûr ça évolue au fil de la mission : de nouveaux inputs viennent enrichir la base, la vision se précise, des questions émergent qui amènent de nouvelles recherches. Mais c'est justement le point, la base de connaissance s'enrichit organiquement au fur et à mesure.
Et enfin un dossier deliverables/ dans lequel les itérations des drafts finaux se construisent. Le document d'architecture, les ADR, les déclinaisons par use case, tout ça est généré à partir de la knowledge, pas à partir de rien.
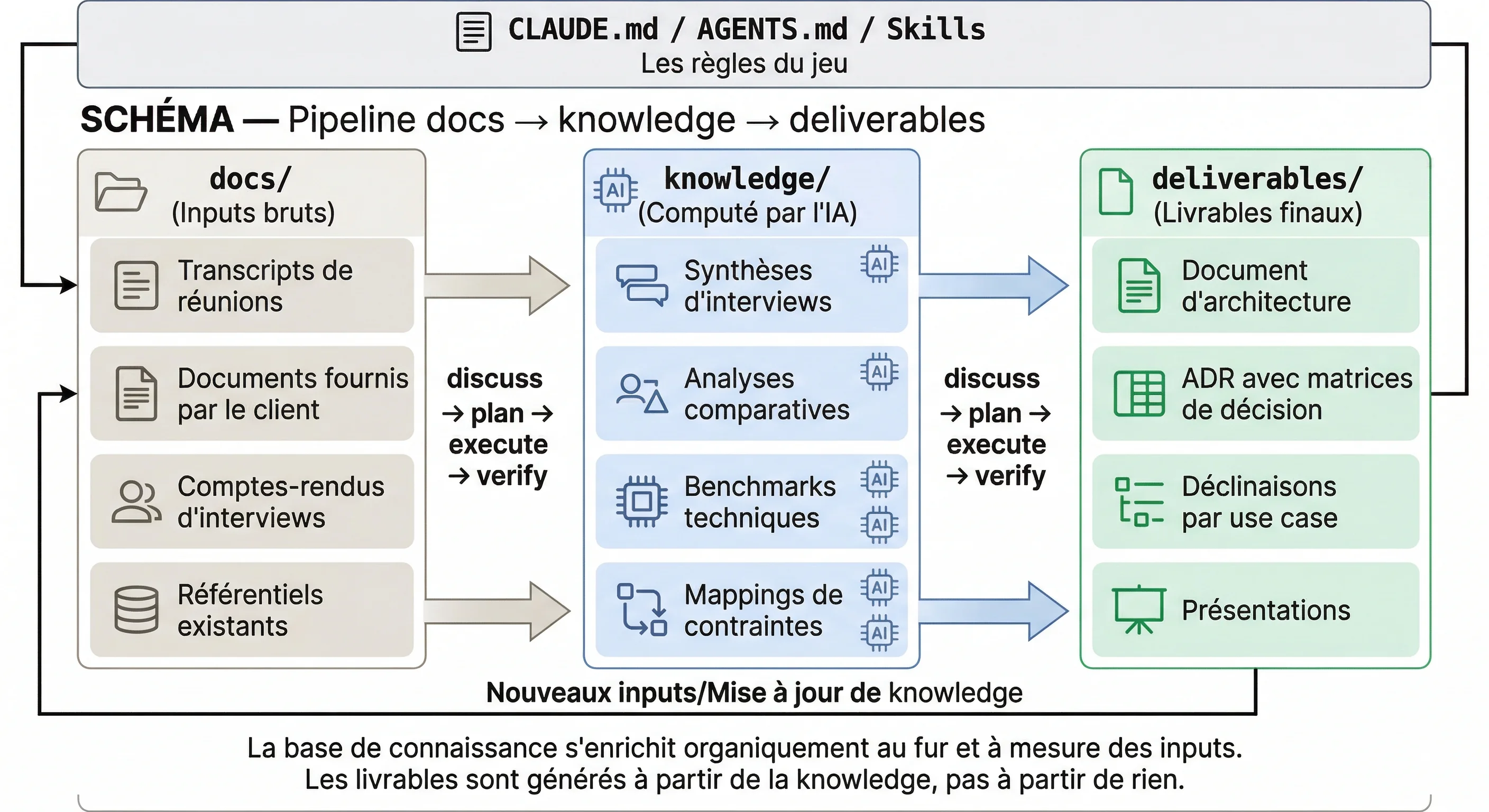
À côté de ça, il y a les règles et instructions de contexte qui résident dans les instructions classiques de Claude ou Codex : CLAUDE.md, AGENTS.md. Des skills sont créées au fil de l'eau pour adresser des sujets spécifiques, comment scorer une matrice de décision, comment structurer un ADR selon le référentiel du client, etc. Tout se construit organiquement.
Chaque décision dans le document final est marquée par un statut : décision prise (avec la matrice de scoring et les arguments), recommandation (avec le curseur d'arbitrage), hypothèse (à valider), validation pending (à confirmer avec une autre équipe). Et le plan GSD vérifie les artefacts documentaires comme il vérifierait du code : "Chaque ADR contient une matrice de décision avec critères pondérés", "Scores argumentés, pas tous 5/5", "Conformité mappée aux principes d'architecture du client". Ce sont des truths vérifiables, même si le livrable est du markdown et pas du TypeScript.
Un autre : gouvernance d'équipe distribuée
Un projet de platform engineering, 10 personnes, 5 streams parallèles. Le livrable : un agent Claude Project configuré comme facilitateur de gouvernance.
L'agent est alimenté par 20 fichiers de connaissance structurés : contexte d'équipe, templates de ceremonies, matrice de dépendances cross-stream, fiches de rôles. Transcript de réunion → Claude extrait les infos → artifact markdown daté + matrice de dépendances mise à jour + propositions de tickets Jira.
Le projet est livré comme un agent opérationnel : le client upload les knowledge files dans un Claude Project, et l'outil continue de fonctionner après le départ du consultant.
L'humain au centre
Aller se taper des recherches sur le web pendant des heures ? L'IA. Concevoir un PowerPoint à partir de choix stratégiques déjà faits ? L'IA. Déduire un document technique de décisions d'architecture ? L'IA. Générer les skills et les scripts qui automatisent le pipeline ? L'IA, qui génère ses propres outils.
Mais conduire les interviews, comprendre le contexte politique du client, sentir quelle solution va passer en comité et laquelle va se planter, arbitrer entre deux options techniques en fonction d'une contrainte business que personne n'a formalisée, ça c'est l'humain. Et ça le reste.
Le livrable vivant : le conseil de demain
Et c'est là que nous arrivons à la thèse de fond.
Ce que nous livrons aujourd'hui
Un consultant classique livre un document. Un PDF, un repo, une archi. Le client reçoit un snapshot figé. Six mois plus tard, le contexte a changé, les décisions sont orphelines, personne ne sait pourquoi tel choix a été fait.
Ce que nous pouvons livrer maintenant
Avec cette approche, nous ne livrons pas juste un livrable. Nous livrons :
Le cheminement : chaque discussion, chaque recherche, chaque arbitrage est documenté dans le repo. Le client ne voit pas juste la conclusion, il voit le raisonnement.
Le savoir : les fichiers knowledge produits pendant le projet (benchmarks, analyses concurrentielles, états de l'art) sont réutilisables. Pas enfouis dans les notes perso du consultant, structurés, versionnés, accessibles.
Les personnes impliquées : qui a été interviewé, quels points ont été soulevés, quelles réserves ont été exprimées.
Un système évolutif : un agent configuré avec tout le contexte du projet, capable de produire de nouvelles versions de n'importe quel document dès que nous lui donnons de nouveaux inputs. Le client change de stratégie cloud ? L'agent reprend les ADR, les met à jour, produit les deltas. Un nouveau stakeholder veut une présentation exécutive ? L'agent la génère à partir de toute la chaîne de valeur, pas uniquement du livrable final.
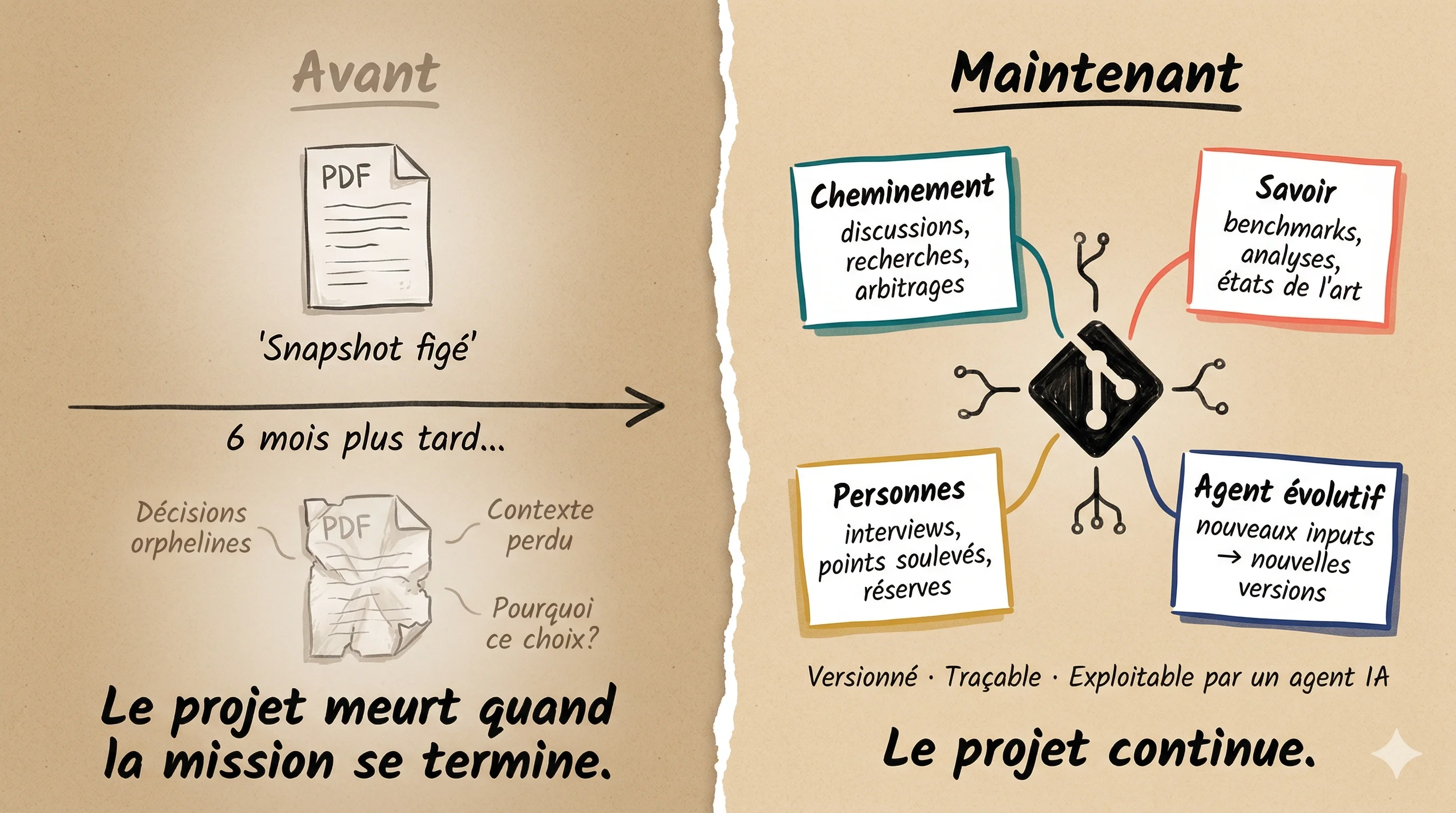
C'est pour moi le conseil de demain, et franchement, c'est déjà celui d'aujourd'hui. Nous ne livrons plus qu'un livrable : nous livrons une approche, un savoir, un cheminement, et un système capable de les faire évoluer dans le temps et de se faire approprier par le client.
Le projet ne meurt pas quand la mission se termine. Il continue.
En pratique : par où commencer
Pour ceux que ça intéresse :
Commencer par un framework structuré. GSD (npx get-shit-done-cc --claude --global), BMAD, ou un autre, l'important c'est de sortir du mode "conversation libre avec un agent" et d'entrer dans un cycle structuré avec de l'état, de la planification et de la vérification.
Ajouter la validation croisée. Une fois que vous avez vos premiers plans et votre premier code, soumettez-les à un autre agent, Codex, Gemini, peu importe. L'important c'est le regard différent, un autre modèle, un autre provider. Vous allez être surpris par les findings.
Tester sur un projet non-code. Prenez un document que vous devez produire, un audit, une analyse, une recommandation, et traitez-le comme un projet dans votre IDE. Dossier documents, dossier knowledge, dossier livrables. Le même cycle discuss/plan/execute/verify. Vous ne reviendrez pas en arrière.
Customiser. Quel que soit le framework, ajoutez vos skills, vos hooks, vos phases custom. Le système s'adapte à vous, pas l'inverse. Et les skills ? Vous pouvez les faire générer par l'IA elle-même.
Conclusion
Nous sommes au tout début de l'ère des meta-agents. Les outils évoluent à une vitesse folle. GSD prépare un v2 en standalone CLI, BMAD pousse sur les Agent Teams, Antigravity propose du multi-agent natif. Si vous vous demandez comment choisir entre ces outils — Claude Code, Antigravity, Codex CLI, Cursor, Mistral et les autres — nous avons publié un comparatif détaillé des IDE agentiques en 2026, qui couvre aussi les stratégies de validation croisée multi-agent décrites dans cet article.
Mais derrière les outils, il y a un changement plus profond. Le form factor du delivery est en train de muter. Un projet, quel qu'il soit, c'est un repo avec des données, du compute, et un livrable. Que le compute soit du TypeScript ou du raisonnement IA sur un document d'architecture, le pipeline est le même.
Le consultant qui comprend ça, qui livre des systèmes vivants plutôt que des PDF figés, c'est celui qui va faire la différence. Pas juste parce qu'il va plus vite. Mais parce que ce qu'il livre a de la valeur après la mission, pas juste pendant.
Et ça, c'est nouveau.
Continuer votre exploration
Découvrez d'autres articles du cluster agentique dans l'univers Intelligence Artificielle