Du Prompt Engineering au Context Engineering : la revanche des ingénieurs
L'évolution rapide des modèles de langage nous pousse à repenser nos approches. Ce qui était hier du "prompt engineering" devient aujourd'hui du "context engineering", marquant un tournant fondamental dans la manière dont nous optimisons les performances des LLM.
Ma vision initiale du prompt engineering
J'étais initialement réticent à l'idée de créer un rôle dédié de "prompt engineer". Ma conviction était que des utilisateurs métier compétents pourraient affiner leurs propres prompts, avec l'intervention ponctuelle d'experts sur les prompts système, sans nécessiter la création d'un poste spécialisé.
Cette vision reposait sur l'idée que la maîtrise des prompts était avant tout une question de compréhension métier et de pratique, plutôt qu'une expertise technique à part entière.
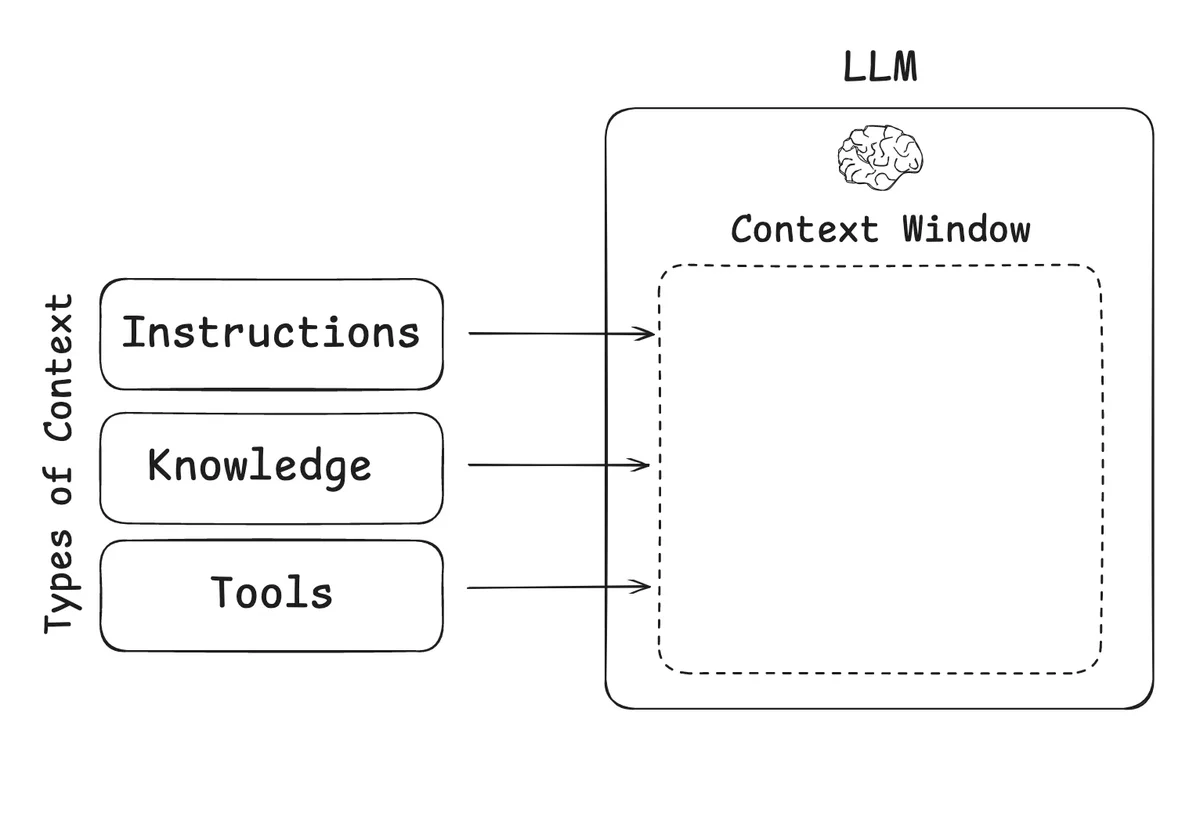
Le passage au context engineering
Avec l'amélioration des performances des Large Language Models (LLM), la maîtrise des prompts devient moins critique. Ce qui compte désormais, c'est la gestion du contexte. Il ne faut pas surcharger les LLM avec des informations excessives et non pertinentes, au risque de dégrader leurs performances.
Cette évolution marque un changement de paradigme : nous passons d'une optimisation textuelle (le prompt) à une optimisation architecturale (le contexte). C'est une transformation qui redonne toute leur importance aux compétences d'ingénierie.
La perspective d'Andrej Karpathy
Andrej Karpathy, figure emblématique de l'IA et ancien directeur de l'IA chez Tesla, apporte un éclairage particulièrement pertinent sur cette évolution :
"Le context engineering est l'art délicat et la science de remplir la fenêtre de contexte avec exactement les bonnes informations pour l'étape suivante."
Selon Karpathy, le context engineering englobe plusieurs dimensions essentielles :
- Descriptions de tâches : Définir précisément ce que le modèle doit accomplir
- Exemples few-shot : Fournir des exemples pertinents pour guider le comportement
- Génération augmentée par récupération (RAG) : Intégrer dynamiquement des informations externes
- Données connectées : Lier les informations de manière cohérente
- Outils : Donner accès aux bonnes fonctionnalités au bon moment
- État et historique : Maintenir une continuité dans les interactions
- Compression : Optimiser l'utilisation de l'espace de contexte limité
L'analogie avec la mémoire RAM
Le context engineering peut être comparé à la gestion de la mémoire RAM d'un ordinateur. Tout comme un développeur doit comprendre les limitations de mémoire et optimiser l'utilisation des ressources, l'ingénieur contexte doit comprendre les mécanismes du modèle et gérer efficacement la fenêtre de contexte.
Cette analogie souligne l'importance de compétences techniques approfondies : il ne s'agit plus simplement de bien formuler une demande, mais de concevoir une architecture d'information optimale.
L'importance pour les systèmes agentiques
Cette compétence devient critique pour développer des systèmes d'information agentiques performants. Les agents IA ne peuvent être efficaces que si leur contexte est parfaitement orchestré, permettant une compréhension profonde de la situation et une prise de décision éclairée.
Les systèmes multi-agents, en particulier, nécessitent une gestion sophistiquée du contexte pour coordonner les différents composants et maintenir une cohérence globale. C'est là que le context engineering révèle toute sa valeur.
Les implications pour l'industrie
Cette évolution a des implications profondes pour l'industrie :
- Revalorisation des compétences d'ingénierie : Les ingénieurs retrouvent un rôle central dans l'optimisation des systèmes IA
- Nouveaux profils recherchés : Les entreprises cherchent des profils capables de combiner compréhension technique et vision architecturale
- Évolution des formations : Les cursus doivent intégrer ces nouvelles compétences de gestion du contexte
- Redéfinition des outils : De nouveaux outils émergent pour faciliter la gestion et l'optimisation du contexte
Le software engineering est toujours là
Le passage du prompt engineering au context engineering marque une maturation de notre approche des LLM. Cette évolution redonne leurs lettres de noblesse aux compétences d'ingénierie traditionnelles, tout en les adaptant aux défis spécifiques de l'IA générative.
Pour les ingénieurs, c'est une opportunité de retrouver une place centrale dans la révolution de l'IA, non plus comme simples utilisateurs d'outils, mais comme architectes de systèmes intelligents complexes. La revanche des ingénieurs n'est pas une victoire sur d'autres professions, mais une reconnaissance de la valeur unique qu'apporte l'expertise technique dans ce nouveau paradigme.
Articles similaires
Continuer votre exploration
Découvrez d'autres articles du cluster fondamentaux-ia-llms dans l'univers Intelligence Artificielle